 The integrated use of Machine Learning (ML) and Business Rules (BR) is one of the most practical trends in the development of modern decision-making software. OpenRules is involved in this development for more than 10 years starting with our successful ML+BR projects for IRS. Along with a general purpose Rule Learner, we also provide Rule Compressor, that uses ML to compress large decision tables to smaller ones. This recent presentation explains how it works. Let’s consider a simple example. We took this decision table
The integrated use of Machine Learning (ML) and Business Rules (BR) is one of the most practical trends in the development of modern decision-making software. OpenRules is involved in this development for more than 10 years starting with our successful ML+BR projects for IRS. Along with a general purpose Rule Learner, we also provide Rule Compressor, that uses ML to compress large decision tables to smaller ones. This recent presentation explains how it works. Let’s consider a simple example. We took this decision table
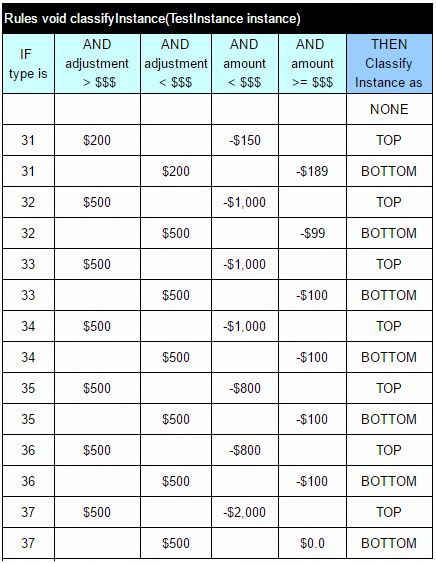
and executed it a regular rule engine against 2,396 test-instances. The classification results gave us a training set for an ML algorithm (RIPPER) which successfully generated these rules:

Are these two rulesets equivalent? At the very least, we know that the generated rule being applied to the same 2,396 test-instances produced exactly the same results in 2,395 cases! It means only one instance was classified incorrectly!
When we applied a similar approach to much larger decision tables, we could receive smaller rulesets that produced “almost the same” results. However, there were always some incorrectly classified cases. In some situations, when a small number of classification errors are acceptable, this could be a good practical approach. No wonder: smaller rules sets require much less maintenance and work much faster! But let’s look at the negative side of this approach. We should always remember that in certain applications the errors could be critical and not acceptable (for example in medical decision making). But more importantly, let look at the above example more attentively. In the manually created rules, the classification was a function of three attributes (type, adjustment, and amount) while the automatically generated rules depend only on one attribute “amount” with a “magic” threshold -159. Is it good or bad? It depends! If we forget an initial ruleset and rely only on the generated one, we will lose the important business logic used by subject matter experts. What if they decide to add another important attribute and the old rules already gone? What if adding more test-instances will bring other attributes to the game?
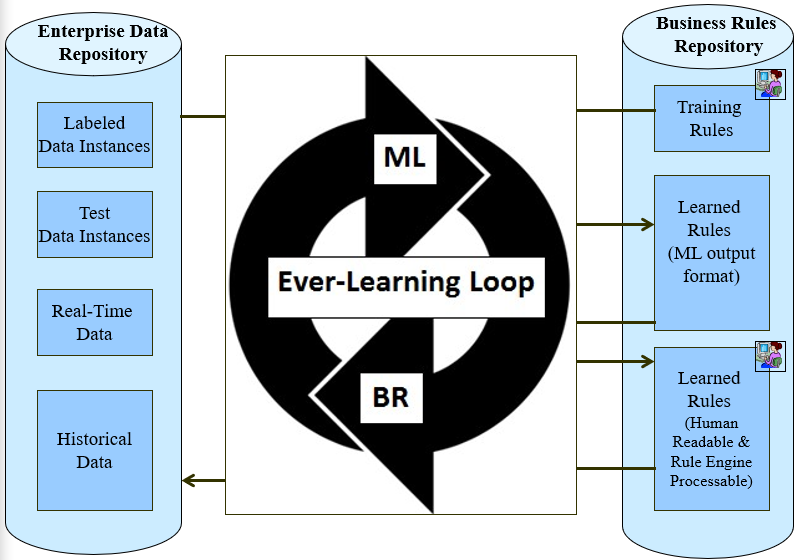
A possible solution is that we never should destroy initial rulesets and maintain them along with the automatically generated rules. This approach is called “Ever-Learning Loop” and is described at this scheme:
Read more here.
