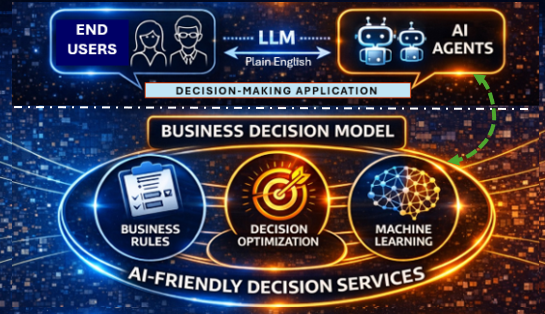
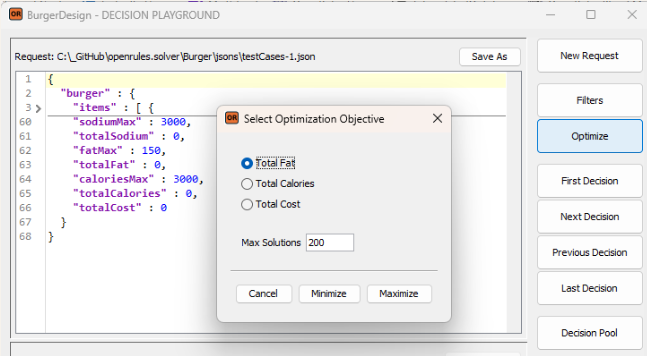
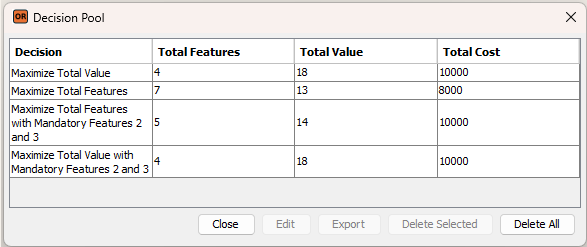
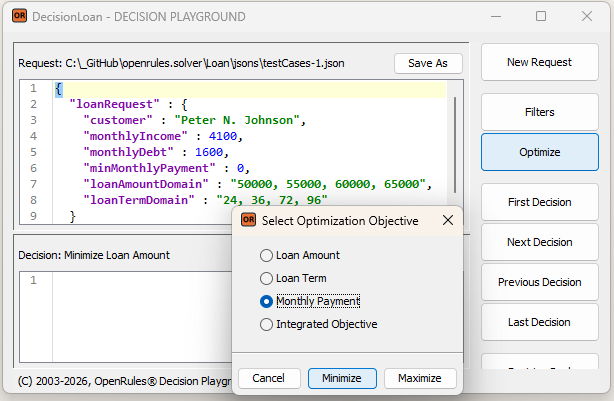
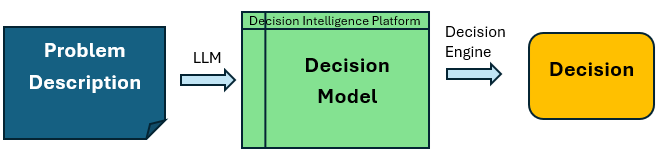
OpenRules Release 12.1.0 introduces the OpenRules AI Assistant — a graphical tool for testing business decision models in plain English and simulating various end-user interaction scenarios.
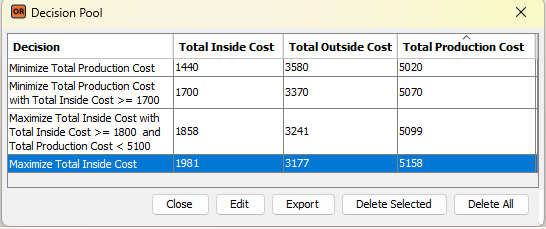
To illustrate its capabilities, we use the “Loan Selection” decision model, which helps bank customers find the right loan. We present an actual dialogue between a loan applicant and the decision model, explain how to configure the OpenRules AI Assistant, and provide the decision model’s implementation details.
Functionally, the OpenRules AI Assistant is similar to other agentic AI assistants such as ChatGPT Codex or Claude Code, which can also work directly with OpenRules-based decision services. What sets the OpenRules AI Assistant apart is that it works directly with the decision model without requiring any deployment and needs no additional prompting to restrict it to the provided decision model.
Try OpenRules 12.1.0 and experience the power of rule-based and optimization-based decision services seamlessly integrated with the latest AI advances — with no hallucinations.