
For years many Rule Engine customers were satisfied with their performance as the majority of rule engines delivered in general good performance. However, the picture changed dramatically in the last 3-4 years when the number of rules-based real-time transactions started to grow from hundreds of thousands or several millions to hundreds of millions per day. The typical execution time of 50-100 milliseconds per transaction what used to be considered as a good performance indicator is not sufficient anymore. Nowadays large customers require the performance that goes down to only a few milliseconds per transaction or in many cases under 1 millisecond. This real-world requirement along with the dramatic shift to cloud-based deployment was the main reason why two years ago we redesigned our Classic OpenRules product and built its new implementation known today as “OpenRules Decision Manager“.
I knew that our Decision Manager improved the performance of the decision services roughly from 10 to 100 times. But being busy with helping our customers and adding new great capabilities to the product, we didn’t have time to do the performance benchmarking. DMCommunity.org Feb-2021 Challenge gave us an opportunity to do it considering different deployment options supported by OpenRules Decision Manager. Finally, I asked our developers to help me to do such benchmarking. Below I will describe what we did.
- Business Decision Model
- Creating Java Benchmark
- Using OpenRules Java API
- Using OpenRules with Docker
- Using OpenRules with AWS Lambda
- Comparing with Brute-Force Java
- Download and Try
- Summary
Business Decision Model. The Challenge deals with only one decision table that determines coverage attributes for various medical services considering various combinations of their attributes. While this table is simple it’s relatively big: it contains 16,369 rules. This table is provided in CSV format along with 10 test cases in JSON. It was easy to convert this information to a working OpenRules business decision model.
We decided to use a OpenRules decision table of the type “BigTable” that utilizes a special execution algorithm (based on the self-balancing binary search) that is much faster to compare with the regular decision tables when they contain a large number of rules. Then we created the glossary:
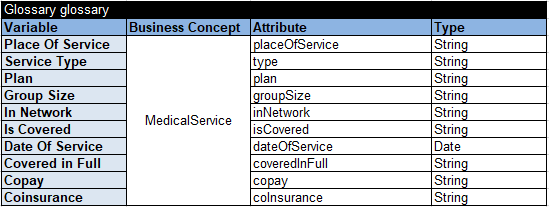
To test this model, we created test-cases in Excel based on the tests provided in the Challenge:
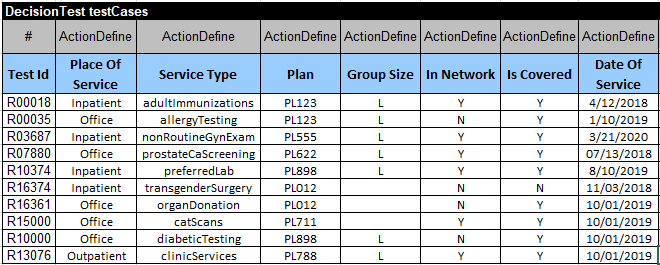
We built this decision model by a simple double-click on the standard file “build.bat“. When we opened this decision model in OpenRules Explorer and it created this Decision Model Diagram:
Then we switched to the Run View and clicked on “ALL TESTS”:
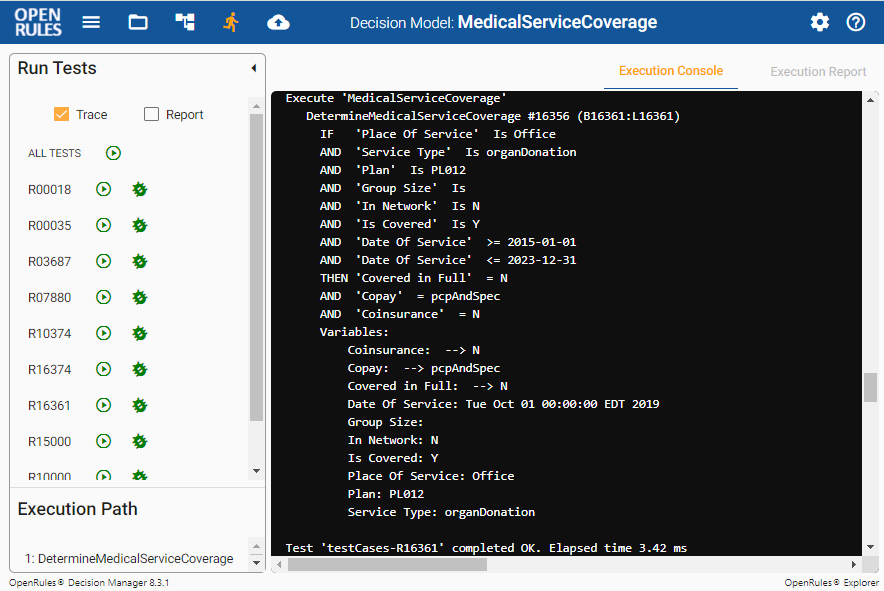
Every test was executed in ~3 milliseconds. It gave a performance idea but obviously could not be considered as a real performance test because of tracing and other graphical overhead. I wanted to create a real benchmarking environment for this problem, run not just 10 requests but thousands of them, and to compare the performance metrics for different deployment options: Java API, Docker, and AWS Lambda.
Creating Java Benchmark. We implemented our benchmark for this problem in the abstract Java class “TestHarness” that is supposed to do the following:
- Read the provided 10 JSON requests and convert them to the array of services represented in the automatically generated Java class “MedicalService”
- Run the test against the test batches that include 10, 1000, 10000, 20000, and 100000 requests.
- Display the execution metrics including
- Average Requests Execution Time (in milliseconds): an average time for execution of one request. This is a complete round-trip time for one transaction that may include a networking overhead related to sending, converting, and receiving requests/responses
- RPS: an average number of executed requests per second (1000/Average Requests Execution Time)
- Total Elapsed Time (in seconds): the total number of seconds for execution of this batch.
Here is the complete code for the Java class TestHarness:
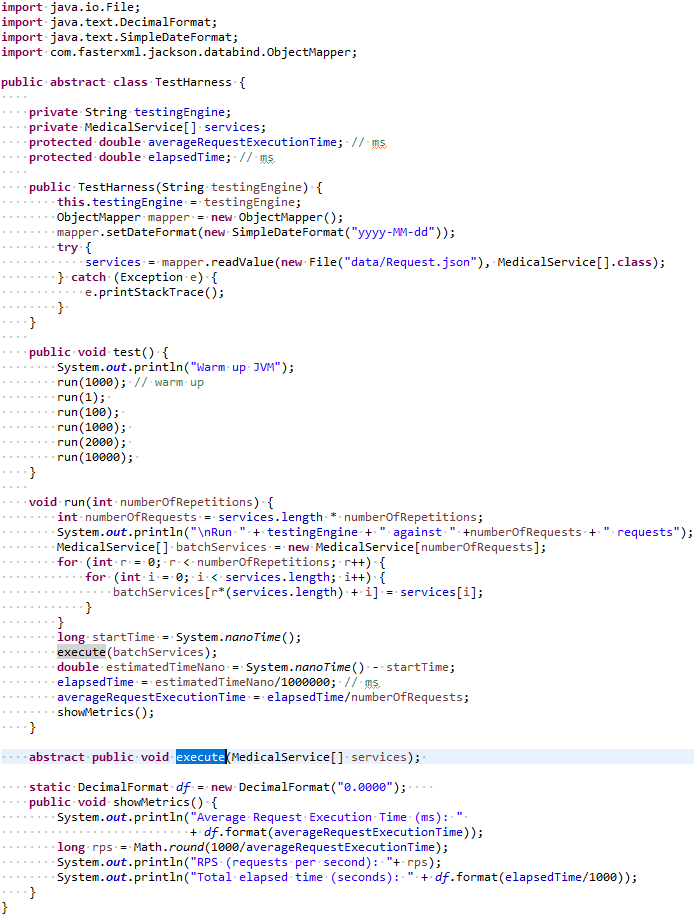
This class has only one abstract method execute(MedicalService[] services) that should be overwritten by subclasses that provide a concrete implementation for the execution of the services.
Please note that the method test() is the same for all execution mechanisms. To keep the performance comparison fair, first it always warms up the JVM before executing different batches. This warm-up is necessary for any Java benchmarking mechanisms to skip time spent for JVM’s lazy class loading and just-in-time compilation.
Thus, for every implementation of this decision service we only create a subclass of TestHarness that implement the method execute(…).
Using OpenRules Java API. During the build of the decision model OpenRules already generated all necessary Java classes used for its execution. So, it was easy to create the class TestHarnessJavaAPI that uses the standard OpenRules Java API as shown below:
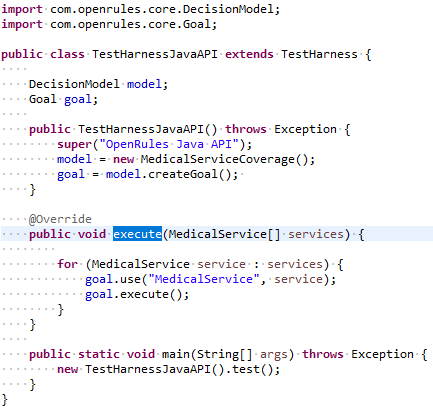
The constructor TestHarnessJavaAPI creates an instance of the DecisionModel using the already generated class MedicalServiceCoverage and creates the main goal. The overloaded method execute iterates over services and executes the goal for each service.
When I executed this class on my laptop, it produced the following results:

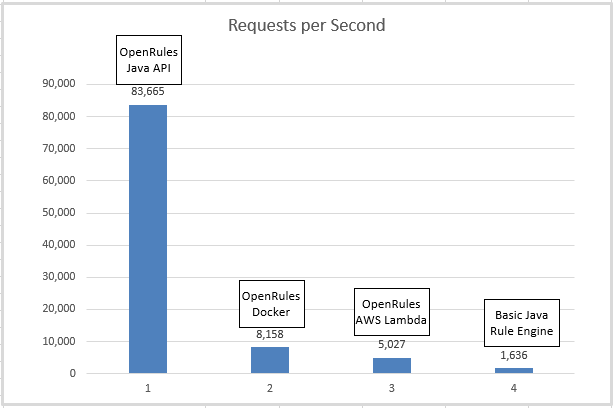
More than 100K requests per second is an impressive result!
Using OpenRules with Docker Container. To deploy our decision model as a Docker container, we did the following:
- Started my Docker Desktop
- Added one property spring.boot=On into the standard OpenRules configuration file “project.properties”
- In the standard file “buildDocker.bat” modified parameter -Dimage=medical-service-coverage. Ran this batch file and it created a new Docker container
- Run the following command>docker run -p 8080:8080 -t medical-service-coverage to start my Docker container. It became ready for execution against multiple request from the endpoint http://localhost:8080/determine-medical-service-coverage.
First, we tested this dockerized service using POSTMAN:
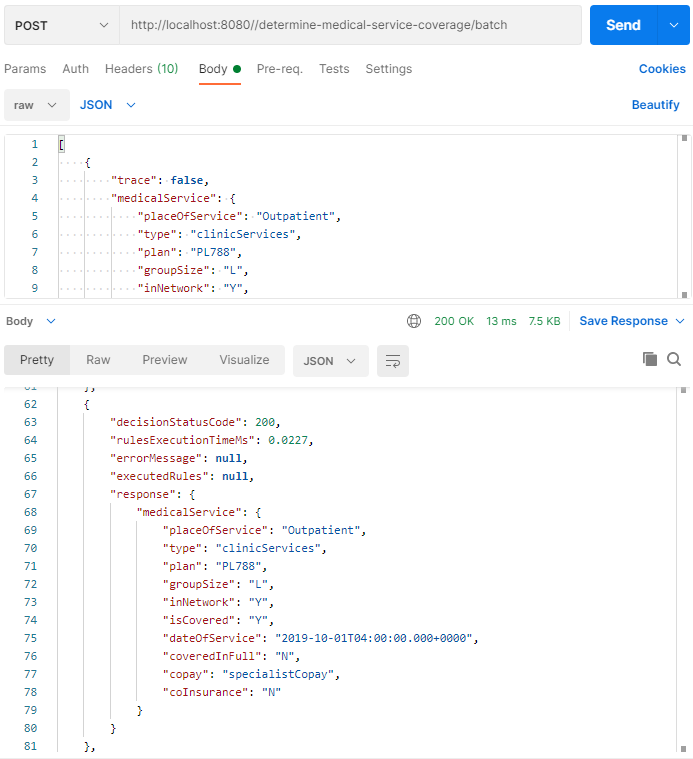
It executed the same 10 request within 13 milliseconds that is much longer to compare with the above pure Java API, the pure evaluation time for one request without overhead was almost the same (see 0.0227 ms in the POSTMAN’s response).
To test this dockerized service using out TestHarness, we created the subclass TestHarnessCloud:
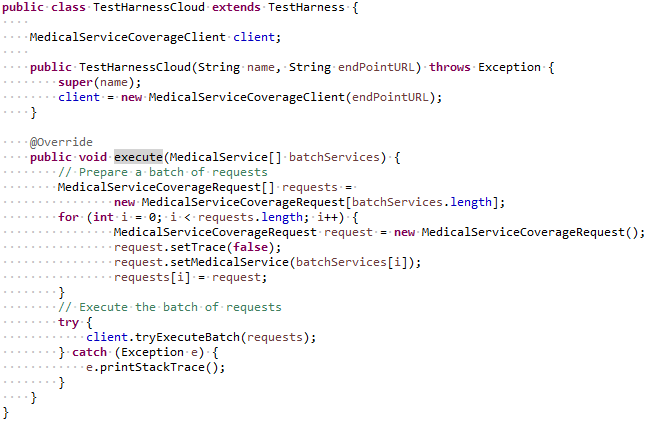
It uses the automatically generated Java classes MedicalServiceCoverageClient and MedicalServiceCoverageRequest. First it creates a client, then a batch of requests, and then asks the client to execute this batch. This subclass can be used to execute any cloud-based services, in particular we will reuse this class for AWS lambda (see below).
To execute our dockerized service within the benchmark, we create a simple launcher:
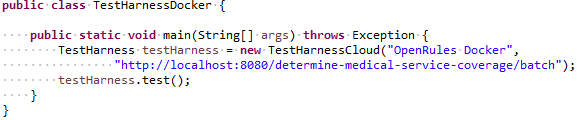
After its execution we received the following results:

Thus, because of the overhead the dockerized service is ~10 times slower to compare with Java API, however handling 8K requests per second (~30M requests per hour) is still a very good result!
Using OpenRules with AWS Lambda. To deploy the same decision model as an AWS Lambda function, we did the following:
- In the file “project.properties” we replaced the the property SprintBoot=On with:
aws.lambda=On
aws.lambda.bucket=openrules-demo-lambda-bucket
aws.lambda.region=us-east-1
aws.api.stage=test
- Ran the standard batch file “deployLambda.bat“. It created a new lambda-function and produced this endpoint URL “https://w7itb80o0g.execute-api.us-east-1.amazonaws.com/test/determine-medical-service-coverage/batch“.
To test this Lambda function we relied on the same class TestHarnessCloud but launched it using the following code:

We received the following results:
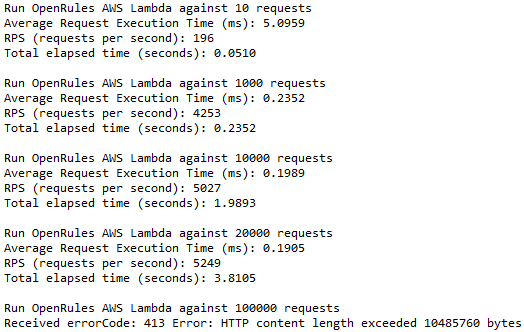
These results are a bit worse to compare with the Docker. Besides, when we tried to execute a batch of 100,000 requests, we hit the AWS API Gateway limitation – an endpoint fails HTTP content exceeds 10485760 bytes. It’s not really a problem as the batches of 10K or 20K are good enough in many practical cases. Please note that the average request execution time for 10 requests is a result of the overhead related to the batch creation. When we tried to execute these 10 requests by calling our AWS Lambda from POSTMAN, we still received an average rule evaluation time 0.0250:
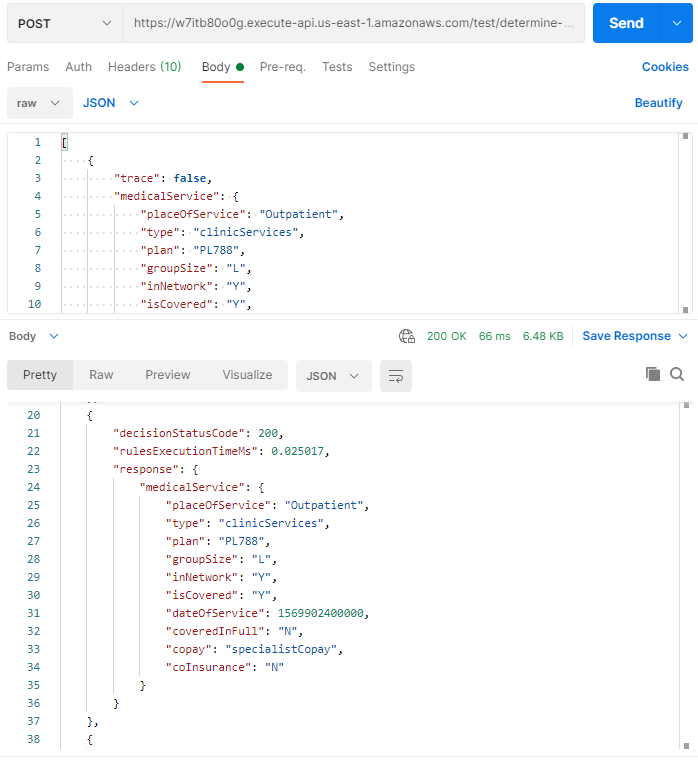
Thus, using the AWS Lambda we still experience a great performance of 5K requests per second or 18M per hour.
Comparing with Brute-Force Java. DMCommunity.org already published a pure Java solution with a specialized rule engine that can handle only this particular problem. As many Rule Engine vendors frequently face a competition with brute-force Java solutions, we decided to compare OpenRules solution with the provided “Java Rule Engine”. We used the provided source code to add the class JavaRuleEngine to our benchmark project. Then we created a subclass TestHarnessJavaRuleEngine that looks as below:

When we ran this JavaRuleEngine, our TestHarness produced the following results:

Comparing execution times for 10,000 requests, this “brute-force” Java solution is 50 times slower than OpenRules Java API and even 3 times slower than our remote AWS Lambda in spite of its networking overhead.
Download and Try. We added all sources to the OpenRules Decision Manager 8.3.2 that can be downloaded from here. It include two new projects:
- MedicalServiceCoverage – with a business decision model
- MedicalServiceCoverageTest – with the described testing benchmark.
We also uploaded the Docker’s image, so everybody could run it and check the performance without installing OpenRules. Download it from http://openrules.com/downloads/my/Docker/medical-service-coverage.image. We assume you already have Docker installed, for instance, you may install a free Docker Desktop just start it. Then from the folder, into which you downloaded medical-service-coverage.image, run the following commands:
>docker load -i medical-service-coverage.image
>docker images – you will see the image ID, e.g. 3f559ff8c8a9
>docker tag 3f559ff8c8a9 medical-service-coverage
>docker run -p 8080:8080 -t medical-service-coverage
It will start the Docker container. Then start POSTMAN with URL http://localhost:8080//determine-medical-service-coverage/batch, take the JSON request available from here, copy it to the Request Body, and click on “Send”. It should execute the dockerized service on your computer, and you will see response including “rulesExecutionTimeMs”.
SUMMARY. We summarized our benchmarking results in the following table:
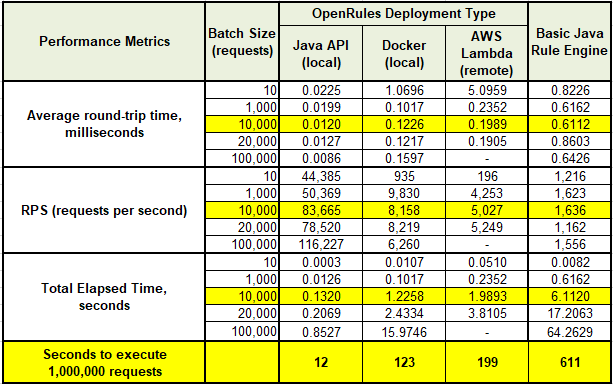
The last row shows the number of seconds required for the execution of 1M requests using different implementations based on the RPS for 10,000 requests.

Pingback: Digital Decisioning Platform
Great achievement!! Would you share the hardware specifications that performed the tests?