This question was asked by Antonio Plais – see the LinkedIn discussion. Several practical variations of this question were mentioned: 1) Define if the same product appears more than once in the same sales order; 2) determine the uniqueness of records in a file to be loaded into a Data Warehouse. Obviously, the question deals with business rules defined on collections of objects – not the most popular topic among decision modelers.
A few “answers” were offered by the discussion participants: 1) Nick thinks that it goes outside a decision model and suggested to do it using a couple of process tasks; 2) Gil noticed that to recognize duplicate records we may need to compare more than one fact types; to do that he recommended to use Repeating Groups from their decision modeling product, but still provided no details how to check uniqueness; 3) Barb offered a 5-steps algorithm that will require a special new operator “List is not appended with”.
Any answer to this question will need to compare objects inside a collection with all other objects using some “similarity rules”. Even if we try to present it in SQL the proper implementation may look somewhat like
SELECT SkuColumn, COUNT(*)
FROM OrderTable
GROUP BY SkuColumn
HAVING COUNT(*) > 1Without even discussing the underlying SQL algorithms this query is far from being “trivial” (while it deals only with one fact type).
Naturally, my first thought was “How would we, at OpenRules, address this question?” We also have our own “repeating groups” (you may find an example here) and we may relatively easy implement something along the lines suggested by Barb. Even adding new operators would not be difficult to do. However, I am afraid the result will be too awkward from a business user perspective.
I perfectly understand Antonio’s desire to introduce a generic operator “Have Duplicates” applied to a collection of objects and not to worry about other implementation details – a decision modeling product should offer the proper construct! Antonio is right – the only reasonable request to a business user is to specify the rules that define duplicate products (“similarity rules”).
Let’s consider a concrete example: we want to define duplicate product lines inside a sales order, when two product lines are considered “duplicate” if they have the same “sku” and “price”.
In our consulting practice, we usually address such requests with a piece of Java code. We do have a predefined Java class BusinessObjectArray that deals with these problems. In particular, it has a method “calculateSimilarObjects(String[] properties)” that defines all duplications inside an array of objects using the “properties” of each object inside the array. This method also sets a Boolean variable “containsDuplicates“. There is nothing special about this class – a regular Java developer may write his/her own variation of it (or just take it from our open source repository).
If I want to use this class, I may inherit a new class SalesOrder from BusinessObjectArray, and then solve the problem with the following Excel method:

However, it is still coding, that Antonio (and I) would not like to offer to our business users. So, I tried to make something more business friendlier within a typical decision modeling context such as TDM or DMN.
As a result, I introduced a new decision table type “DecisionTableUniqueness” that should hide all implementation details. At the same time, our business user should be able to create a decision table that may look as follows:
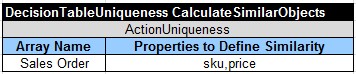
As you may guess, this decision table has only one unconditional action (conclusion) called “ActionUniqueness” with two sub-columns: 1) Array Name that is a Sales Order in our case; 2) Properties that define object similarity which are properties “sku” and “price” of our class Product. That’s it! Almost as Antonio wanted – just instead of an operator “Have Duplicates” we defined a new column type “ActionUniqueness” inside traditional decision tables (rule families).
I do not want you to think that something magic has happened behind the scene. It is quite natural for OpenRules to add new decision table types using custom rules templates. So, in the spirit of the open source, below I will describe my entire test project including decision tables, glossary, test data, produced results, as well as the decision template.
I created two very simple Java classes (beans):
- SalesOrder that is simply inherited from BusinessObjectArray and nothing inside
- Product that is a simple Java bean with 3 properties: sku, price and quantity.
Everything else (logic) is defined within Excel. I started with the test data:
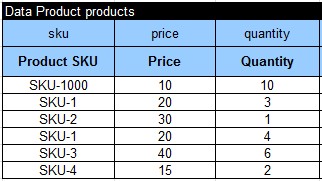
Then I decided that my decision will have two sub-decisions:

The first sub-decision will calculate similar objects – see the proper decision table “CalculateSimilarObjects” above. The second sub-decision will check the variable “Contains Duplicates“, filled by the first sub-decision, to produce a message about possible duplication:

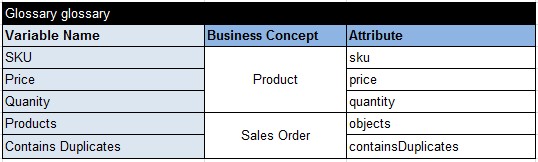
And here is the proper glossary:
When I ran this decision model, it produced the following results:
*** Decision DetermineUniqueness ***
Decision has been initialized
Sales Order contains duplicate products from DetermineProductUniqueness
Decision Output:
BusinessObjectArray:
Product [sku=SKU-1000, price=10, quantity=10]
Product [sku=SKU-1, price=20, quantity=3] 1 duplicate(s)
Product [sku=SKU-2, price=30, quantity=1]
Product [sku=SKU-1, price=20, quantity=4] 1 duplicate(s)
Product [sku=SKU-3, price=40, quantity=6]
Product [sku=SKU-4, price=15, quantity=2]
This array contains duplicates
Our decision model correctly diagnosed that the second and the fourth products are duplicates.
And finally, the custom template for the table of the type “DecisionTableUniqueness” is described by this Excel table:

It’s quite similar to the initial method “CalculateSimilarObjects” but the important fact is that a business user would never see this template – we will probably add it to the OpenRules library of optional templates, so it could be reused.
At the end I want to thank Antonio Plais for initiating an interesting discussion.
