
DMCommunity.org Challenge May-2022 still has no submitted solutions. I knew that the problem is not as simple as it sounds because we, at OpenRules, have quite a few claim processing customers, whose decision models address similar and much more difficult problems. When I tried to create a decision model for this challenge, I quickly got a solution that still produced these errors while processing a test-claim:
[E71.313] cannot be reported together with [E72.3]
[E72.3] cannot be reported together with [E71.313]
But the challenge specifically required not to produce duplicate errors. Trying several decision modeling approaches, I built a few “tried-and-failed” decision models before I came up with two solutions which I feel comfortable enough to share here.
Decision modeling professionals usually recommend the top-down approach, but in this case it may distract us forcing to concentrate up-front on how to select needed pairs of diagnoses. It may lead us to creation of intermediate lists of matching and not-matching diagnoses, etc. Alternatively, we may use the bottom-up approach and start with the situation when the pair (Diagnosis 1; Diagnosis 2) has been already selected. Then we simply need to look for these diagnoses in the CSV file using the following logic:
IF (Diagnosis 1 found in the Column1 AND Diagnosis 2 found in the Column2)
OR (Diagnosis 1 found in the Column2 AND Diagnosis 2 found in the Column1)
THEN Report the error “Diagnosis 1 cannot be reported together Diagnosis 2”
SOLUTION 1
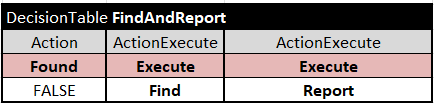
It is easy to represent this logic in different tools. Using OpenRules, I created two decision tables “Find” and “Report”. The first table “Find”

is a single-hit table with two rules. The first rule is trying to find a row in the file “ICDCodes.csv” for which Diagnosis 1 is in the Column 1 and Diagnosis 2 is in the Column 2. If found, it sets the temporary decision variable “Found” to TRUE and stops. If not, the second rule will do an alternative search. Note that I used here the table of the type “BigTable” that guarantees a superfast execution to compare with the regular DecisionTable.
The second table “Report”

simply adds the proper error message to the array “Errors” if the variable Found was set to TRUE by the previous table. This representation is simple and intuitive. To invoke these two decision tables one after another with setting Found to FALSE I created this table:
How to invoke FindAndReport for different pairs of diagnoses reported in the claim? This is not a trivial question. Being a Java developer, it was quite easy for me to write this Java method (still in Excel):

Those people who are familiar with basic Java or C can quickly understand that here I used two loops iterating over the same array “Diagnoses”. The second (nested) loop uses only those diagnoses which were not selected yet in the first loop. After I added a simple Glossary

my first decision model was completed. Then I execute it against all test cases presented in this table:

I received the results that were expected. This decision model is simple enough and produces all correct solutions. However, how about business users who are not familiar with basic Java or C and do not want to see any code?
SOLUTION 2
Here is how I replaced the above Java code “IterateDiagnoses” with the following decision tables which use the latest OpenRules “ActionLoop“:
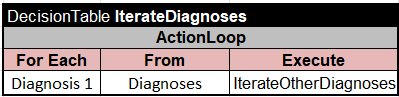


As you can see, the first ActionLoop iterates through all Diagnoses using the variable “Diagnosis 1” as its current diagnosis. Similarly, the second ActionLoop (invoked from the first one) iterates through the same Diagnoses using the variable “Diagnosis 2” as its current diagnosis. To avoid duplicated pairs, I needed to introduce an intermediate array “Already Selected Diagnoses” into which I add “Diagnosis 1” before starting the second (embedded) loop. Then before calling “FindAndReport” the third table validates that “Diagnosis 2” Is Not One of Already Selected Diagnoses. After I added the array “Already Selected Diagnoses” of the type String[] to the above Glossary, the modified decision model produced exactly the same expected results and did it without Java!
Deploy and Run AWS Lambda
And finally, I decided to deploy this model as AWS Lambda function and test it from POSTMAN. To do this, I added deployment properties to the OpenRules configuration file “project.properties”:

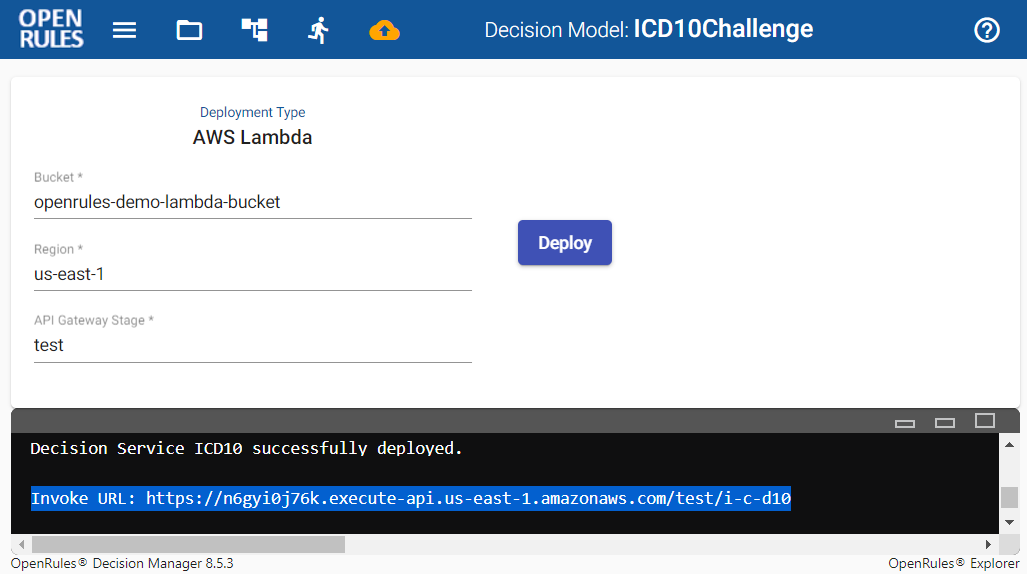
OpenRules Explorer had shown this decision model as below:

I selected the Deployment Views, and clicked on the button “Deploy” (I could do the same using the standard file “deployLambda.bat”). It created a new Lambda function using an AWS OpenRules account with the endpoint URL highlighted below in blue:
I copied this URL and pasted it to the POSTMAN. All test cases were automatically converted by OpenRules into the proper JSON format and placed in the folder “jsons”. I copied and pasted the 3rd test to the POSTMAN’s input in the following view:
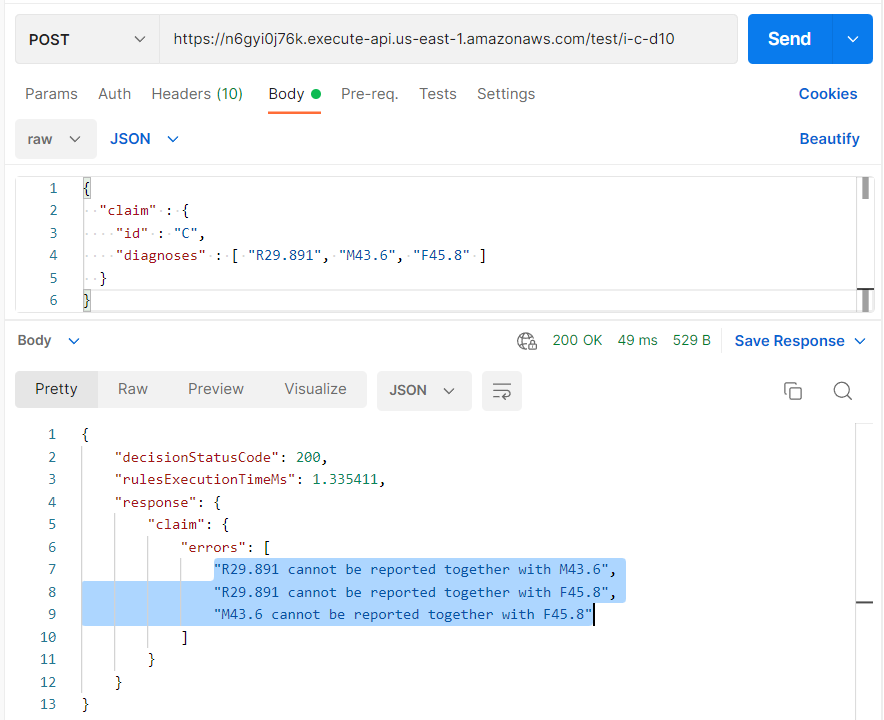
As you can see, it took POSTMAN only 1.3 milliseconds to execute my decision service (or 49 milliseconds including networking).
P.S. I plan to use this challenge during my DecisionCAMP-2022 presentation. But as I wrote above, I did not come up with these nice and relatively simple solutions right away. Initially, I used much more complex implementations that still failed to produce the correct results. As this experience reflects real-world situations, I want to share the “bad” decision models as well. That’s why I plan to call my presentation “Decision Modeling: Good, Bad, and Ugly“.
