
This is the name of the DMCommunity.org Aug-2021 Challenge that is supposed to predict survivors of the Titanic tragedy based on partially known actual results. Dr. Bob Moore has already submitted a very good analysis of this challenge and applied several ML-based approaches to solve it. It inspired me to ponder the same challenge from a bit different angle. I thought I could try two approaches: 1) using common sense or human prejudice-based rules to predict who could survive; 2) using our very simple Rule Learner to let ML algorithms to do the same. I spent almost the whole day today working on this problem, and this post describes what and how I did. It is interesting to compare the final results:

Problem Description (from DMCommunity.org)
Kaggle is a popular competition website for Machine Learning (ML) professionals. Its legendary Titanic competition is quite simple: use ML to create a model that predicts which passengers survived the Titanic shipwreck. Kaggle offered two CSV files: train.csv – a list of 891 passengers with their various characteristics like age, sex, ticket class, fare, and more; test.csv – a list of other 418 passengers with similar characteristics. Both lists include the field “Survived” that contains 1 if the passenger survived or 0 – if not. The first list should be used as a training set to discover the survival rules, and the second list should be used only to test the accuracy of the discovered survival rules. Note that not all characteristics are known, e.g. for some passengers age is not specified. Many good solutions have been provided since 2012.
In our challenge, we want you to download and use the same two csv-files to create and test a special decision service called “Titanic Booking Service”. First, you should create a decision model with rules that produce one of the following advices for each passenger: 1) Bon Voyage; 2) Go at your own risk; 3) Don’t do it!
You can create rules using any ML tool or manually following your own analysis of the data and your interpretation of the Titanic tragedy (“hints from the future”). You even may borrow some rules discovered by Kaggle‘s competitors. What you cannot do is to feed your ML tool with passengers who should be used for testing only.
At the end your decision model should apply these rules against every of 418 test-passengers, giving them a booking “advice”, comparing them with what actually happened to each passenger, and producing the summary with total numbers of Good and Bad advices.
Use your favorite BR/ML/DM tool to create and run this decision service. We plan to announce winners (people who produce the largest numbers of Good advices) at DecisionCAMP in September.
Testing Harness
As we already got the test instances, it’s only natural to start with the testing harness into which we could include any prediction rules: created manually or discovered by an ML algorithm. So, I took the provided file test.csv and added to it the standard OpenRules title rows:
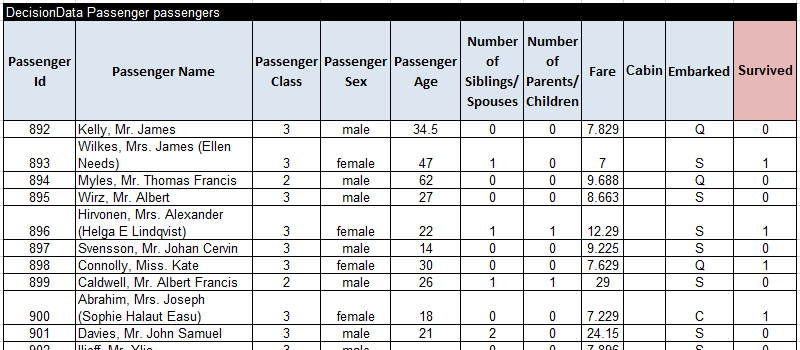
This table contains 418 passengers for which we know if they survived (1) or not (0).
Then I added the glossary:
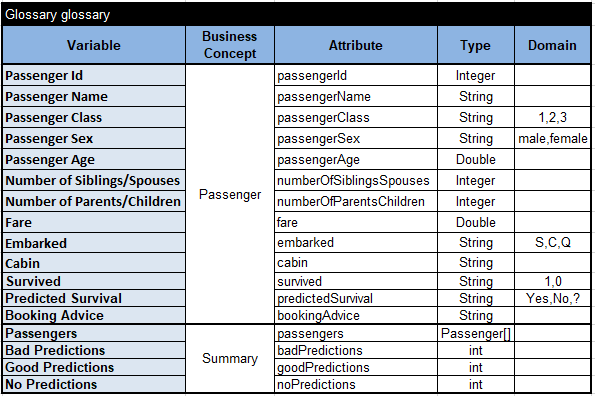
For the business concept “Passenger” this glossary contain all decision variables used in the test data table with their attributes, types, and possible domains. I also added here two more decision variables:
- Predicted Survival – the decision variable that should be defined by our future prediction rules
- Booking Advice – the text advice that our booking services should produce, e.g. Bon Voyage or Don’t do it!
I added one more business concept “Summary” that along with the list of Passengers contains the numbers of Good Predictions, Bad Predictions, and No Predictions produced by our future prediction rules. The above problem formulation states (at the very end) that they are looking for solutions that produce the largest numbers of Good advices. But does it constitute a Good Advice”?
Probably it depends on how the Predicted Survival is close to the actual. If they are the same it is a good prediction and vice versa. But considering that we not always could produce any advice, I decided to create the following decision table:
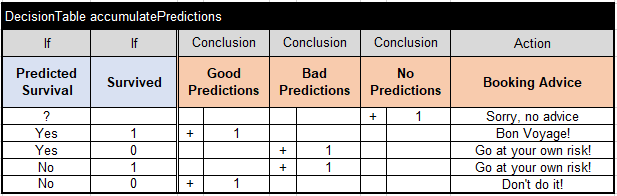
This table being executed for every already classified passenger will accumulate the proper number of predictions and specify the Booking Advice.
To complete our testing harness, we need to be able to iterate over all test-passengers using the following table:

It initializes all prediction counts and start iteration over Passengers applying the following rules “ClassifyOnePassenger” to each passenger:

The decision table “accumulatePredictions” is already defined above, and now we also specified the name of the decision table “classificationRules” that will be used to determine Predicted Survival of each passenger.
The classification rules can be defined manually of using any ML algorithm. To make sure that out Test Harness works, I started with the trivial classification rules when every woman survives and every man dies:
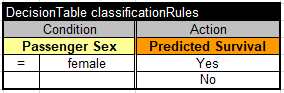
Bob Moore noticed that these rules are true for all provided test-passengers but of cause we cannot rely on this “hint from the future” as there could be different selection of passengers. To run this decision model, I added a little Java launcher that prints the accumulated results:
public static void main(String[] args) {
// Create a decision model and its goal
DecisionModel model = new Titanic();
Goal goal = model.createGoal();
// Create a summary with test-passengers
Summary summary = new Summary();
summary.setPassengers(passengersArray.get());
goal.use("Summary", summary);
goal.execute();
// Print the result
System.out.println("Passengers=" + summary.getPassengers().length +
"\n No predictions=" + summary.getNoPredictions() +
"\n Bad predictions=" + summary.getBadPredictions() +
"\n Good predictions=" + summary.getGoodPredictions());
}
When I ran this launcher it produced the following results (confirming that Bob was right):
Passengers=418 No predictions=0 Bad predictions=0 Good predictions=418
Now I needed to create more sophisticated classification rules manually and using ML algorithms.
Manual Classification Rules
To determine more realistic classification rules manually, one needs to analyze the provided training file train.csv that lists 891 passengers with their various characteristics like age, sex, ticket class, fare, and more. I did not have time (and a desire) to do it. However, after so many years passed after the actual tragedy and after so many movies and books created about it, we all have approximate opinions (or prejudices) of who and why survived and who and why not. Let’s list some of them:
- Very rich ladies (those who travelled in the first class) probably survived
- Many rich and strong people probably survived (we may assume they are men and women between 20 and 50 who travelled in the first or second class)
- Young children who travelled with parents probably survived (being saved by the parents)
- Young males between 15 and 30 even if they travelled in the second or third class probably survived
- Other people probably did not survived
Of course, we could expand/modify this list, but let’s try to implement it and run inside our test harness. Here are the proper decision table:
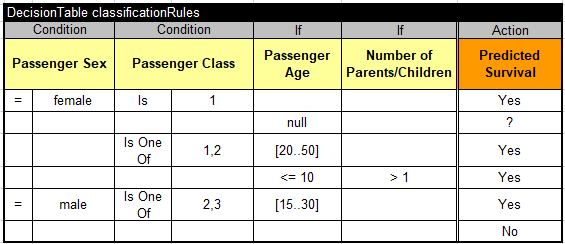
Note that the second rule is needed to handle the passengers with unknown age for whom we can not produce any advice. When I replaced the trivial classification rules with these rules, my test harness produced the following results:
Passengers=418 No predictions=84 Bad predictions=205 Good predictions=129
I tried several more variations of similar rules with prejudice, but still the bad predictions always exceeded the good ones. I even added all passengers from the provided training set to the list of test-passengers, but the results were not much better:
Passengers=1309 No predictions=252 Bad predictions=550 Good predictions=507
So, I decided to finally apply our ML-based rules discovery using our simple Rule Learner.
Machine Learning Rules Discovery
OpenRules Rule Learner allows anybody without serious knowledge of machine learning and programming to apply powerful off-the-shelf ML algorithm to discover rules from historical datasets. A user just need to create two Excel tables:
- Training Instances such as already provided in the file train.csv
- Glossary which we already created above but only with decision variables included in the training instances.
It was easy to add two top rows to the provided file train.csv:
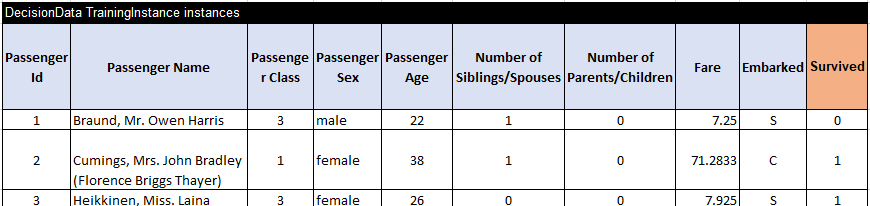
This file has 891 training instances. I was able to run Rule Learner as a SaaS directly from AWS: https://saas.rulelearner.com/. I don’t need to download anything. I simply uploaded the file “Titanic.xls” with these two tables inside. Then I clicked on the button “RUN RULE LEARNER”. It applied the default ML algorithm RIPPER to quickly produce the classification rules as shown below:
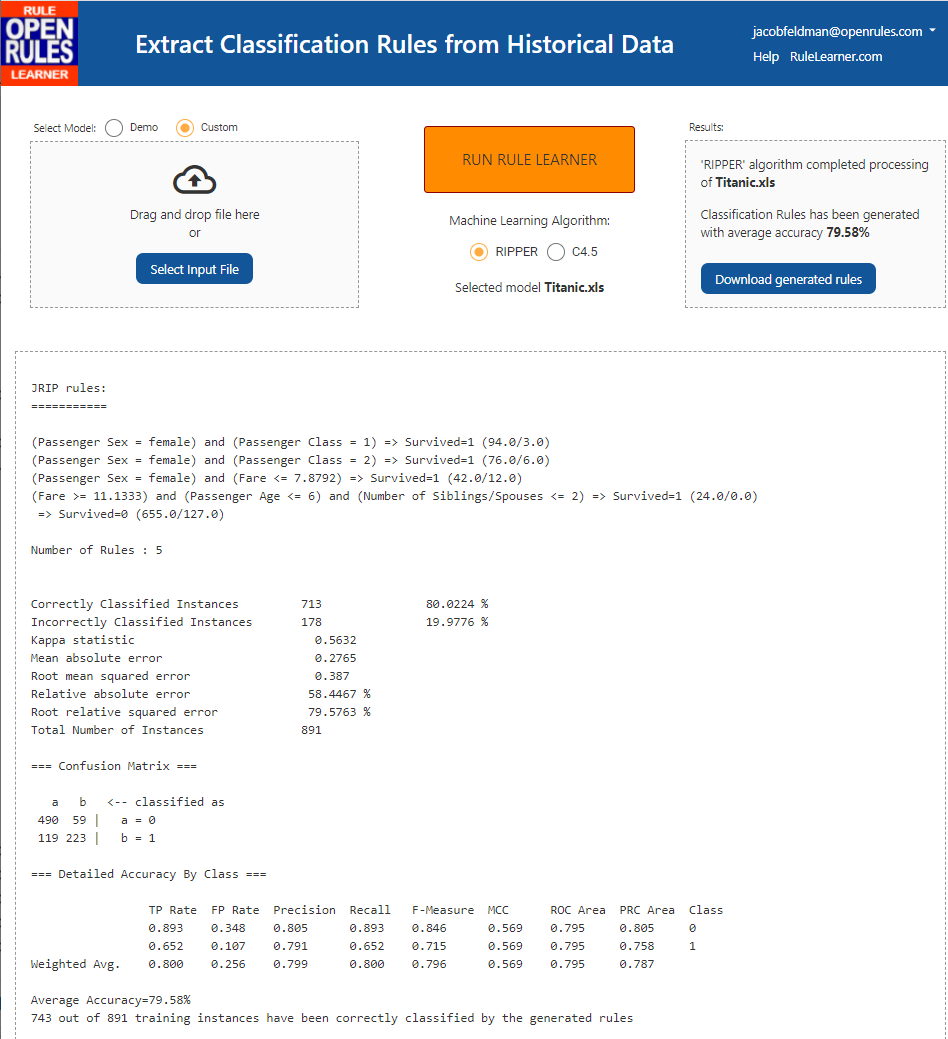
I clicked on the button “Download generated rules” and received the file “GeaneratedRiles.xls with this automatically generated rules:
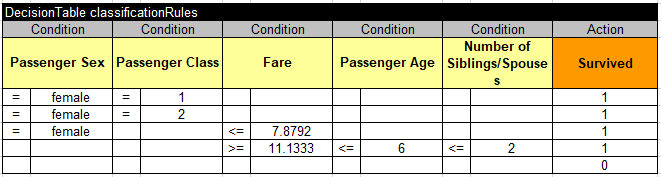
Here are the produced accuracy metrics:
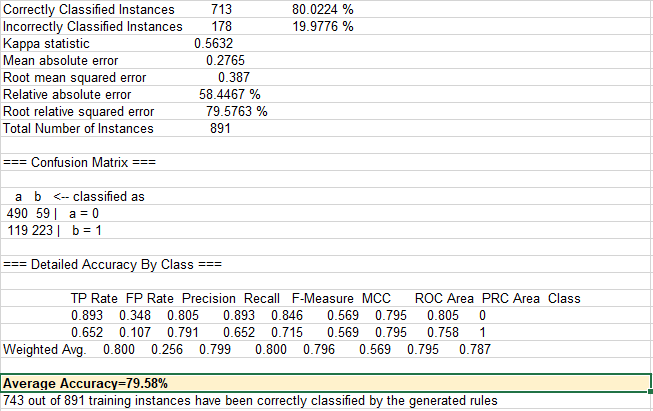
To fit my Test Harness expectations, I needed to modify the last column of this table in Excel by changing “Survived” to “Predicted Survival”:

Then I replaced the manual classification rules with these rules in my Test Harness, and ran it. Here are the produced results based on the rules discovered by RIPPER:
Passengers=418 No predictions=0 Bad predictions=52 Good predictions=366
These results seem to be much better to compare with my manual attempts.
To complete the exercise, I decided to run Rule Learner to check which results I will receive by running another ML algorithm. So, I ran Rule Learner again this time selecting c4.5 algorithm:

As you can see the average accuracy is almost the same (79.24%) but the generated rules are completely different because C4.5 generates a decision tree:
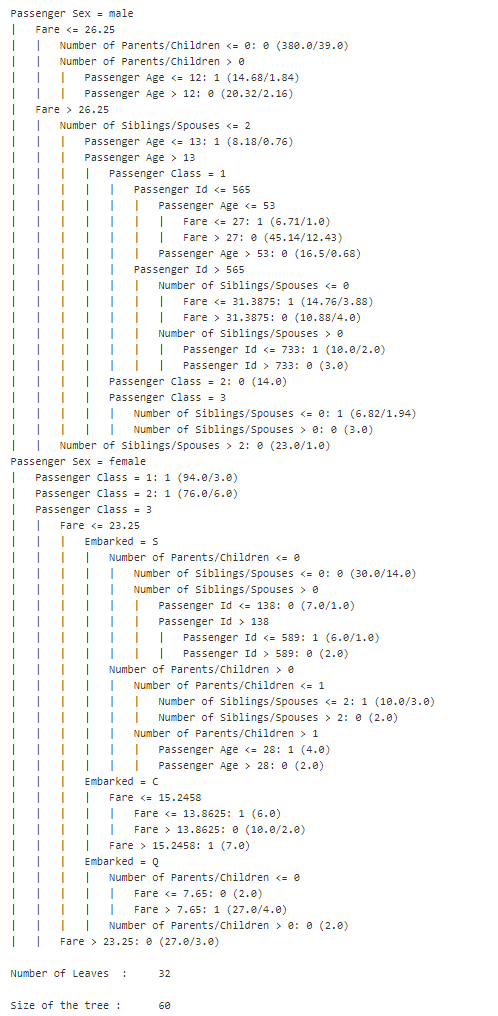
But when I downloaded these rules, Rule Learner transformed them into the decision table (I modified only the last column):
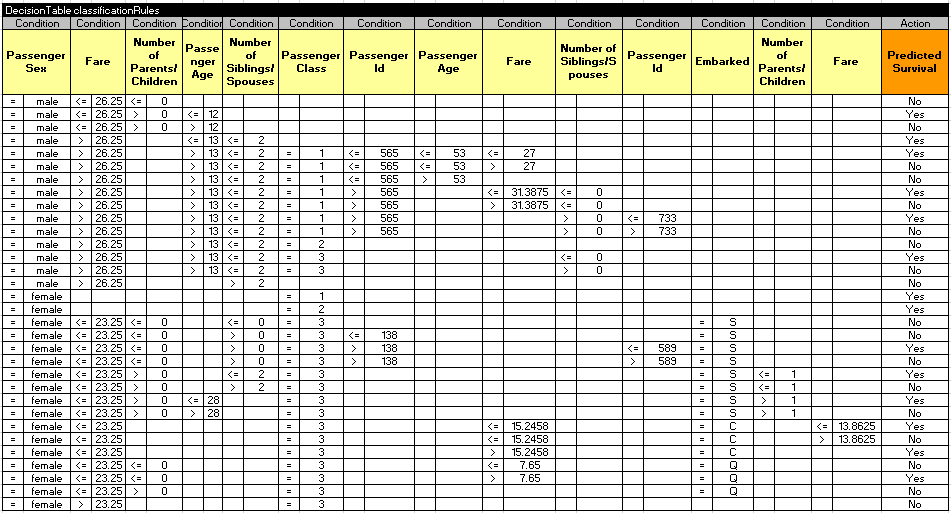
Here are the produced accuracy metrics:
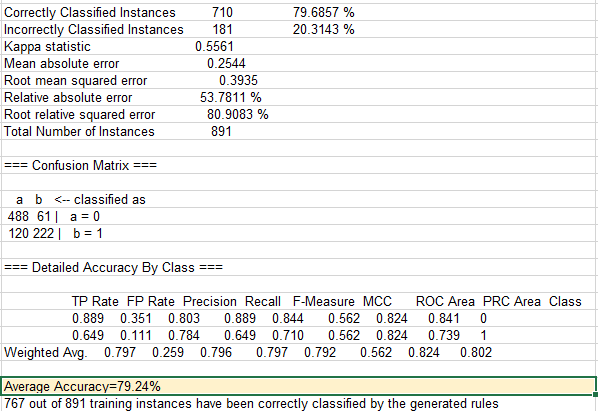
And finally here are the execution results from the Test Harness when “classificationRules” generated by C4.5 were applied:
Passengers=418 No predictions=0 Bad predictions=68 Good predictions=350
SUMMARY
