 The DMC Challenge Sep-2020 deals with compression of decision tables trying to replace relatively large decision tables with “almost” equivalent but smaller decision tables. It is only natural to apply Machine Learning to this problem as it allows us to automatically discover business rules from the sets of labeled historical data records. So, I decided to use the open source Rule Learner to address this problem. In this post I will describe how I approached this problem with these implementation steps:
The DMC Challenge Sep-2020 deals with compression of decision tables trying to replace relatively large decision tables with “almost” equivalent but smaller decision tables. It is only natural to apply Machine Learning to this problem as it allows us to automatically discover business rules from the sets of labeled historical data records. So, I decided to use the open source Rule Learner to address this problem. In this post I will describe how I approached this problem with these implementation steps:
- Write a simple generator of data instances with various combinations of known attributes
- Run the existing decision table using OpenRules to produce labeled instances
- Feed the labeled instances to Rule Learner (or SaaS Rule Learner) to automatically discover a new decision table and evaluate its performance.
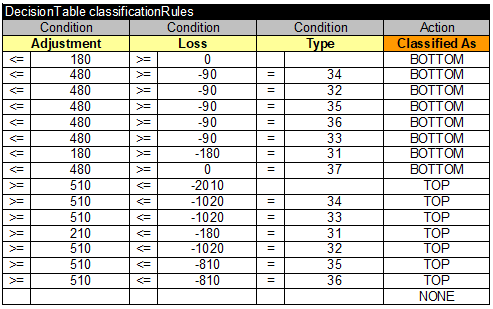
The challenge provides this manually created decision table:

and we should try to discover another decision table that will work in the same (or almost the same) way on different new data instances. The target decision table should be able to define the attribute “Classify As” for new instances in almost the same way as the above table does.
Data Instance Generation. Many decisioning platforms (e.g. SAPIENS, Corticon) can automatically generate test instances for given business rules. In our case, it was a very simple task: we can navigate through all possible types from 31 to 37, the through possible adjustments from 0 to say 800 with a certain step, e.g. 30, and then through possible losses from 0 to -2500 with a step=-30. So, I quickly wrote a Java program with 3 embedded loops that looks as follows:
BufferedWriter writer = openFile("generated.csv");
DecisionModel model = new DecisionModelCompress();
Goal goal = model.createGoal();
int n = 0;
int step = 30;
for (String type : types) {
Instance instance = new Instance();
instance.setType(type);
for(int adjustment=0; adjustment < 800; adjustment += step) {
instance.setAdjustment(adjustment);
for(int loss=0; loss > -2500; loss -= step) {
n++;
instance.setId("T"+n);
instance.setLoss(loss);
goal.use("Instance", instance);
goal.execute();
System.out.println(instance);
writeToFile(writer, type + "," + adjustment + ","
+ loss + "," +instance.classifiedAs);
}
}
}
closeFile(writer);
This program uses the DecisionModelCompress that consists of a single decision table from the challenge to which I added first two lines to the top:

Playing with different step-values I can generate the file “generate.csv” that looked as follows:

For step=30 this file contains 15,876 labeled records.
Rules Generation. Then I created an Excel file “Compress.xls” that I wanted to give to SaaS Rule Learner as an input to generate rules based on these 15,876 training instances. The file “Compress.xls” contains two tables:
- Training instances copied from the file “generate.csv” (only a few instances are shown):
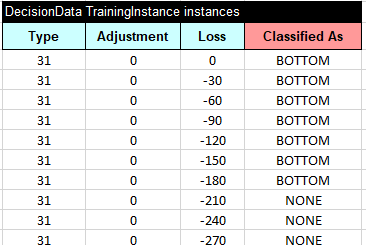
- Glossary:
 Rule Learner quickly generated the following rules:
Rule Learner quickly generated the following rules:
It is interesting that this automatically generated decision table (single-hit) looks very similar to the initial decision table (multi-hit) and contains almost the same number of rules. It also produces the following metrics (with respect to over-fitting):
| Average Accuracy=99.99% (the weighted F-Measure) |
| 15876 out of 15876 training instances have been correctly classified by the generated rules |
On the large data set it produces almost perfect results but does not really compress our original decision table.
Then I decided to increase the navigation step from 30 to 100 to produce much less training instances. The generated “generated.csv” now contains only 1,400 labeled records. When I gave these records as training instances for Rule Learner, it produced the following decision table:

It produces the following metrics:
| Average Accuracy=97.71% |
| 1364 out of 1400 training instances have been correctly classified by the generated rules |
It actually compressed our initial decision table – instead of 15 rules it contains only 6 rules. However, Rule Learner warns us that we may lose a small percent in the accuracy, meaning some new instances would not be correctly classified. This table was produced by applying the machine learning algorithm “RIPPER” known for producing the most compact sets of business rules.
Then I decided to use the same training set but to apply another machine learning algorithm “C4.5” that usually produces a larger set of rules in a form of a decision tree. The Rule Learner converted the generated decision tree into the following decision table:

with the following metrics:
| Average Accuracy=100.0% |
| 1400 out of 1400 training instances have been correctly classified by the generated rules |
Like me, you probably will be surprised not only by seeing 100% accuracy but also by the fact that some attributes like “Loss” were repeated 3 times – it’s a natural result of the decision tree representation. Of course, you need to be a subject matter expert to understand the business nature of the concepts Type, Loss, Adjustment and to judge which generated rules are acceptable and which are not.
CONCLUSION. Machine Learning tools can provide a practical foundation for compression of large decision tables. However, as they do not guarantee the equivalence of the automatically generated and manually created business rules, you always may expect a certain degree of inaccuracy in classification of new instances. So, the practical use of the decision table compression differs from case to case. If your rules produce warnings or recommendations and small mistakes are acceptable, then the automatically generated rules could be the way to go. It is especially true if the cost of maintaining large decision table is too big or it is even impossible to manually create and maintain constantly changing business rules. However, if a classification mistake could lead to huge losses, you should stay away from it. That’s why it’s so important that automatic rules discovery should be done by subject matter experts capable to evaluate (and if necessary to adjust) the generate rules. See, the discussion about “Ever-Learning Decision Models” at http://RuleLearner.com:

