 DMCommunity.org June-2017 Challenge is looking for the best decision models that implement a well-known Loan Origination problem described in in the Section 11 of the DMN specification. So, I decided to address this challenge using the core DMN constructs implemented in OpenRules. I will describe my solution in the form of dialog between a fictional READER who is assumed to be a business analyst (not a programmer) and the AUTHOR, who represents myself. It is similar to the dialog-sessions described in my recent book “DMN in Action with OpenRules“. While it may look long it doesn’t omit any implementation detail. Besides serving as a good solution for the Challenge, this document describes a good decision modeling practice for OpenRules customers.
DMCommunity.org June-2017 Challenge is looking for the best decision models that implement a well-known Loan Origination problem described in in the Section 11 of the DMN specification. So, I decided to address this challenge using the core DMN constructs implemented in OpenRules. I will describe my solution in the form of dialog between a fictional READER who is assumed to be a business analyst (not a programmer) and the AUTHOR, who represents myself. It is similar to the dialog-sessions described in my recent book “DMN in Action with OpenRules“. While it may look long it doesn’t omit any implementation detail. Besides serving as a good solution for the Challenge, this document describes a good decision modeling practice for OpenRules customers.
AUTHOR. Nice to see you again. After our previous sessions, I assume that you feel comfortable using DMN with OpenRules. So, today I expect you to help me to address this Challenge. It deals with a loan origination problem and we will follow decision logic described in details in the DMN spec.
READER. As you asked me before this session, I’ve already had a chance to analyze the implementation provided in the DMN Section 11. I have to tell you that it looks somewhat confusing to me, especially the use of duplicated names, tables, and functions which we never discussed with you.
AUTHOR. Keep in mind, that the Section 11 didn’t even try to describe a good decision modeling practice: it’s actual objective was to demonstrate various DMN constructs including function and other boxed expressions (which I prefer to avoid).
READER. Actually, I’ve also looked at the implementations described in the Bruce Silver’s book. I like them much better but have to admit that his decision models are quite complex.
AUTHOR. The problem itself is not simple. The Challenge is looking for decision models which can be considered as well-designed “from business decision modeling, execution, and further maintenance perspectives”. And today you and me will try to build a really good, working decision model for this problem.
— Problem Depiction — top
Let’s start with the DRD (Decision Requirement Diagram) from the spec redrawn without the BKMs and knowledge sources:

Not to cloud the schema, I omitted arrows (information requirements) between the input objects (Applicant, Requested Product, Bureau Data) and decisions. Please note that I added a high-level decision that determines Loan Origination Result that gives our DRD a single output point.
READER. This DRD looks simpler to compare with the spec. However, it also has two different boxes (decisions) for “Pre-Bureau Affordability” and “Post-Bureau Affordability” while the calculation logic for Affordability is the same. Would we be able to combine them in one decision?
— Top-Down Decomposition — top
AUTHOR. We will not use this schema as an executable DRD, but only as an initial graphical depiction of our problem. And we will address your concerns later on when we discuss “Affordability”. We will start our decision modeling process with top-down decomposition as recommended by Bruce Silver, James Taylor, and other leading DMN methodologists. First, we will decompose our “big” decision model into small loosely coupled decision models.
READER. Loosely coupled?
AUTHOR. Yes, for example a decision model “Affordability” may be a good example of a stand-alone decision model that could be used by decision models “Bureau Strategy” and “Routing” without being tied to them. So, first we will build a “library” of relatively small, loosely coupled decision models which could be executed independently. It will allow us to link various decision models from this library together to model our “big” problem as long as many other related problems.
— Decision Model “Loan Origination Result” — top
On the very high level, our decision model should determine “Loan Origination Result” as “ACCEPT”, “DECLINE” or “REFER”. Looking at the business process defined in the spec on Fig. 69, we may conclude that the decision variable “Loan Origination Result” only depends on variables “Bureau Strategy” and “Routing”. It’s only natural to describe these dependencies in the following decision table:

READER. This is a very simple single-hit decision table. Many other decision tables in the spec are also quite simple, so if you don’t mind I will create decision tables for Bureau Strategy, Bureau Call Type…
AUTHOR. Not so fast. I recommend first to present this piece of decision logic as the first example of a stand-alone decision model which called “DetermineLoanOriginationResult”. As usual, we should create its own glossary and test cases to make sure that it is well defined. We will create a separate folder “LoanOriginationResult” and will will put the above decision table into the file “Rules.xls” inside this folder. Let me complete this work and you will handle other decision models.
I’ve also created the file “Glossary.xls” inside the folder “LoanOriginationResult” that contain the following glossary:
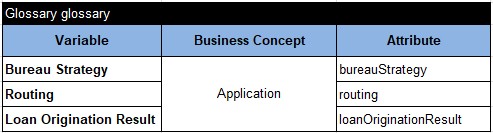
READER. I can see that you simply copy-pasted 3 decision variables from our only decision table to the first column of this glossary.
AUTHOR. And I made them to belong to a new business concept “Application” (the second column) as they do not belong to our input business concepts such as “Applicant”, “RequiredProduct” or “BureauData”. I even do not have to mention these concepts as this decision model don’t have to know about them. The third column contain “technical” names of the decision variables to map them with test or actual data objects.
I will also create the file “Decision.xls” that contains two tables:


The first table “Decision” will be used for a stand-alone testing – in this particular case it will simply execute our only decision table “LoanOriginationLoan”. The Environment table describes the internal structure of our decision model pointing to the files Glossary.xls, Rules.xls, and to the relative path to the standard OpenRules templates.
READER. Now if we define test data we should be able to execute this model.
AUTHOR. I will create the file “Data.xls” with the following tables:
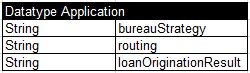

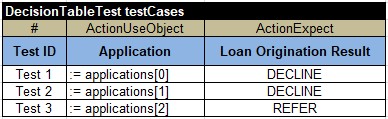
The first table defines our Datatype “Application”, and the second one defines the array “applications”, which elements have type “Application” and provide different values for our decision variable that will be used for testing. And finally, here are our test-cases with expected results:
I want to use this example to recommend you a generic structure of our Rules Repository as depicted below: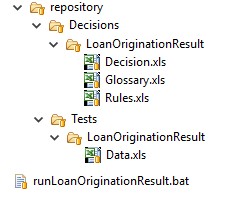
READER. I can see that you created two separate folders “Decisions” and “Tests”. They contain sub-folders such as “LoanOriginationResult” for different loosely coupled and separately tested decision models. The file “Data.xls” goes to a sub-folder of “Tests”…
AUTHOR. … and we can execute test-cases from this file using the standard batch-file “runLoanOriginationResult.bat”. Here are the execution results:
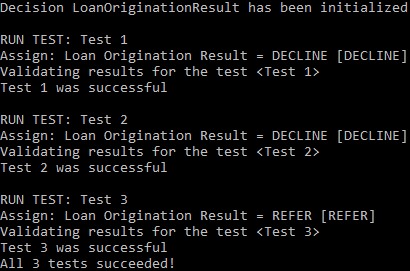
Now you may proceed with creation of other decision models.
— Decision Model “Bureau Strategy” — top
READER. OK, I will start with the decision model “Bureau Strategy”. First I created sub-folders “BureauStrategy” in the folders “Decisions” and “Tests”. The decision logic described in the spec as
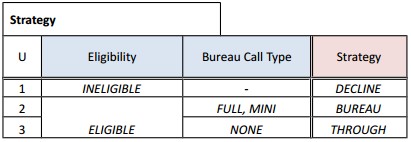
and can be easily presented in OpenRules as follows:

Should I stop here and make it a separate decision model?
AUTHOR. I don’t think it’s practical to pack every decision table as a separate decision model. I’d suggest to include in the decision model “DetermineBureauStrategy” at least one more logical level covering Eligibility and Bureau Call Type.
READER. OK, here are the proper decision tables from the spec:
 AUTHOR. As this logic will be used as a loosely coupled decision model, it do not have to “know” the the Risk Category is defined for Pre-Bureau processing. So, I’d recommend yo to call the proper decision variable “Risk Category” instead of “Pre-Bureau Risk Category”.
AUTHOR. As this logic will be used as a loosely coupled decision model, it do not have to “know” the the Risk Category is defined for Pre-Bureau processing. So, I’d recommend yo to call the proper decision variable “Risk Category” instead of “Pre-Bureau Risk Category”.
READER. OK, I will represent this logic by creating the following OpenRules decision table in the file “Rules.xls”:

Now, let’s look at the Eligibility logic presented in the spec as below:
AUTHOR. Here again from the perspective of our loosely-coupled decision model we may simply use the decision variable “Affordability” instead of “Pre-Bureau Affordability”.
READER. Great! I represented this logic in the following OpenRules decision table:

AUTHOR. Good. I noticed that you used “-” for the not-applicable conditions as in the spec but forgot to add it to the Age for the second rule. You should not worry as OpenRules will handle “-” and empty cells in the same way.
READER. The affordability logic is quite complex, and probably deserves to be placed in a separate, loosely-coupled decision model.
AUTHOR. Agree. Just complete this decision model by creating files Glossary.xls, Decision.xls, and Data.xls.
READER. This glossary should include the decision variable “Age” that belongs to the business concept “Applicant”. And while I can add new decision variables to the concept “Application”, I probably do not need to mention the variables this model does not use, e.g. Routing and Loan Origination Result. Here is my version of glossary:
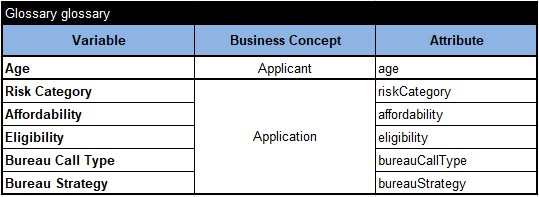
AUTHOR. Thus, in a way the Glossary becomes a view of an independent decision model to the surrounding world.
READER. I like it: each loosely-coupled decision model has its own view. Contrary to previous decision model, this one consists of 3 sub-decisions implemented by the above decision tables. Should I add them to the table “Decision” in the file “Decision.xls”?
AUTHOR. No. This file will be used only for testing purposes. So, it is better to add another table of the type “Decision” to the file “Rules.xls”. It may look as follows:
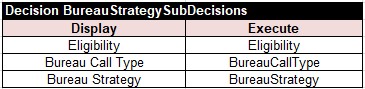
READER. OK. Now I can call this table from my decision “DetermineBureauStrategy” in the file Decision.xls:

And finally, I put in the file “Data.xls” my test data. Here are my Datatype and Data tables for business concept “Applicant”:

Here are my Datatype and Data tables for business concept “Application”:
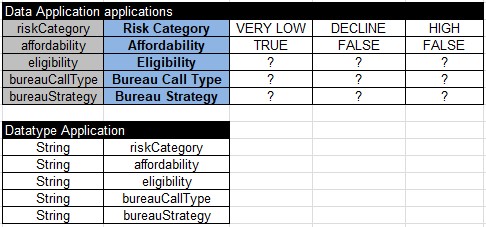
Here are my test-cases with expected results:

I adjusted “runBureauStrategy.bat” and running these tests it produced the following results (shown for Test 1 only):
AUTHOR. Very good. Now our library includes two loosely-coupled decision models, which are already tested and represented in the following file structure:
As our decision modeling process goes in the top-down fashion, the next natural choice of the decision model is “DetermineRouting”. Please proceed.
— Decision Model “Routing” — top
READER. OK, here are the routing rules from the spec:
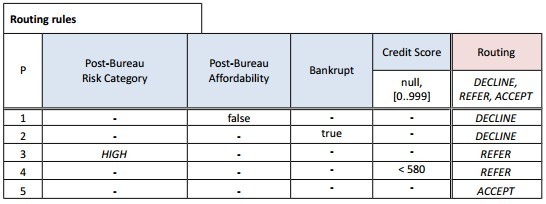 AUTHOR. The spec used here the hit policy “P” simply to demonstrate this type of hit policies. As you know, I don’t recommend to use priorities, so please switch to a regular decision table.
AUTHOR. The spec used here the hit policy “P” simply to demonstrate this type of hit policies. As you know, I don’t recommend to use priorities, so please switch to a regular decision table.
READER. I also prefer to slightly rearrange the columns, and here is my single-hit decision in the OpenRules format:

Like for the Bureau Strategy I use the decision names “Affordability” and “Risk Category” instead of “Post-Bureau Affordability” and “Post-Bureau Risk Category”.
AUTHOR. And you are right, because when this decision model will be executed as a part of the post-bureau or pre-bureau processing the actual values of the decision variables “Affordability” and “Risk Category” would be defined outside of this decision model.
I also like the way you applied a stair-like approach inside your rules going from the left to right and top to bottom. It shows that you actually covered all possible combinations. Why did you leave Risk Category for the last two rules empty?
READER. Because we already analysed Risk Categories DECLINE and HIGH, and I didn’t want to create 4 additional (but identical) rules for 3 remaining categories (MEDIUM, LOW, VERY LOW). Basically in this case, the empty cell means “others”.
AUTHOR. Very good. Please complete this decision model in the already established way.
READER. The above rules use variable “Bankrupt” and “Credit Score” that are defined inside business concept “Bureau Data”. So, my glossary will look as follows:

Here is my decision: Here are my test data:
Here are my test data:


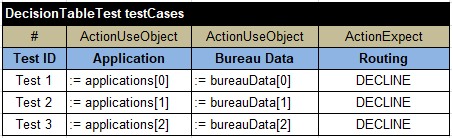 When I ran “runRouting.bat” I received all expected results.
When I ran “runRouting.bat” I received all expected results.
— Decision Model “Affordability” — top
AUTHOR. Going down to the next level of our DRD, we need to concentrate on the next model that we will call “DetermineAffordability”. It is described if the middle part of our DRD: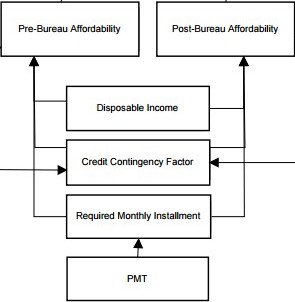
As it will be a stand-alone decision model, we do not have to differentiate between Pre-Bureau Affordability and Pre-Bureau Affordability and will use only one decision variable “Affordability”.
While the spec use affordability logic as an opportunity to demonstrate the use of different boxed expressions, I’d recommend you to stick to basic decision tables. You are again in the driver’s seat.
READER. OK, “Affordability” is a boolean decision variable that should be TRUE only when
Required Monthly Installment < Disposable Income * Credit Contingency Factor
So, I can create a top-level decision table for this model that may look as below:
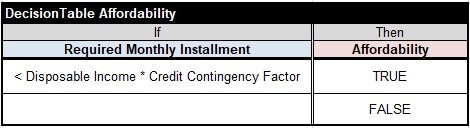
Now we need to specify a decision logic for calculation of 3 variables used in the condition if this table. Let’s start with the Disposable Income which depend only on attributes of our Applicant:
The Required Monthly Installment can be calculated using the following decision table:
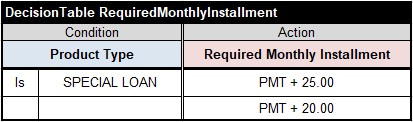
The calculation formulas inside the action uses another decision variable “PMT” that can be calculated using the standard repayment formula:

And finally we may calculate Credit Contingency Factor using the following decision table:

This decision table use the decision variable “Risk Category” that we already used in the decision model “Bureau Strategy”. As you said, this decision model also should not worry how this variable will be actually calculated during pre-bureau and post-bureau processing.
AUTHOR. Yes, you successfully used very basic decision tables with DMN FEEL formulas without necessity to rely on functions, contexts, and other DMN FEEL expressions. You should probably add the table “AffordabilitySubDecisions” that links all these decision tables together (similarly to what you did for the decision model “Bureau Strategy”.
READER. Here it goes:
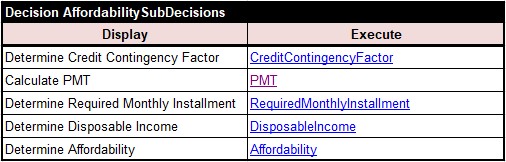 AUTHOR. I can see that this time you use Excel hyperlinks to the automatically created bookmarks to simplify navigation through different decision tables within the file “Rules.xls”. That’s a small representation trick but it will be very helpful during the decision model maintenance.
AUTHOR. I can see that this time you use Excel hyperlinks to the automatically created bookmarks to simplify navigation through different decision tables within the file “Rules.xls”. That’s a small representation trick but it will be very helpful during the decision model maintenance.
READER. Yes, it already was helpful to myself. Now I need to define a test-decision in the file “Decision.xls”:

And finally, I will defined the glossary and test data for this model. The glossary will include all decision variables used by the above decision tables and distribute them between business concepts “Applicant”, “Application”, and “RequestedProduct”. Here it is:
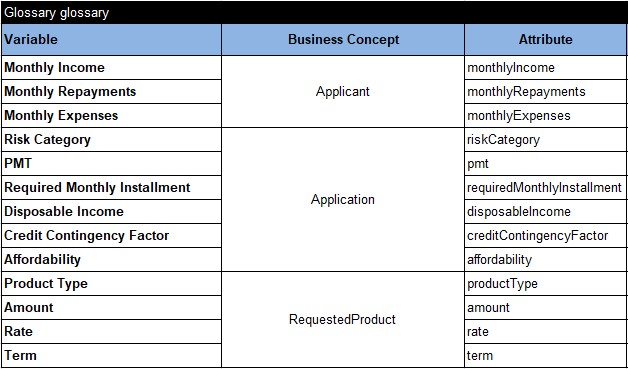
top
AUTHOR. Note that even if your glossary includes other decision variables which are not used by this decision model, it would not create any problems. OK, let’s define test data and run your model.
READER. Here are Applicant data tables:
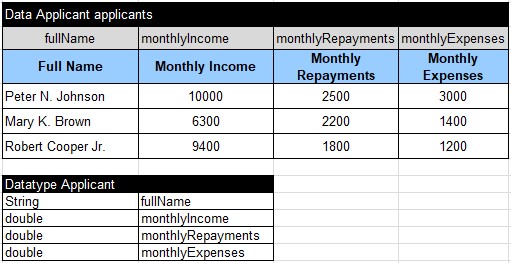
Here are Application data tables:
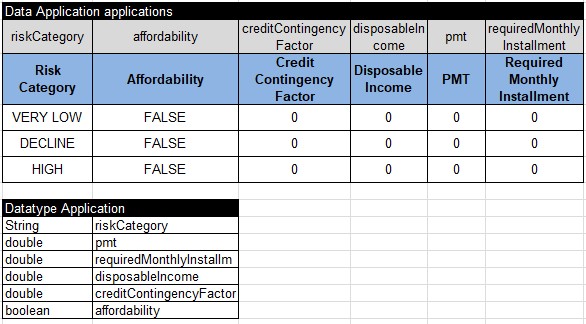
Here are Requested Product data tables:
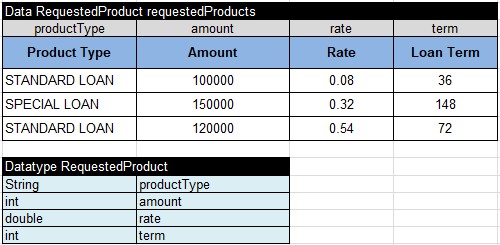
And here are test cases with expected results:

As usual, all data tables are located in the file “Data.xls”. When I executed these tests, I receive the expected results as for the Test 1:

AUTHOR. Very good. Now you actually addressed your own initial concern about necessity to use two different type of affordability for Pre-Bureau and Post-Bureau processing while the calculation logic is the same. You loosely-coupled decision model will serve in both cases. We have only two 3 decision variables whose calculation logic is not specified yet:
- Pre-Bureau Risk Category
- Post-Bureau Risk Category
- Application Risk Score
How would you suggest to represent decision logic that defines these variables?
— Decision Model “Application Risk Score” — top
READER. I’d start with the decision logic for calculation of the Application Risk Score as it depends only on the Applicant’s attribute. Here is the corresponding multi-hit decision table (a scorecard):
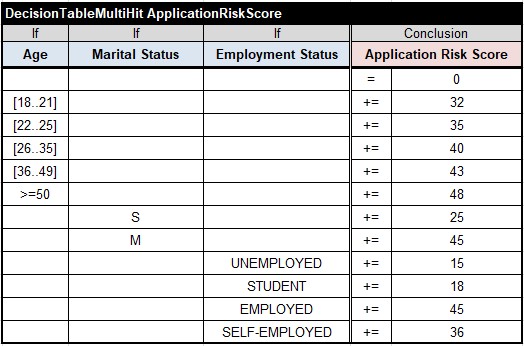
AUTHOR. I like the fact that you explicitly initialize the Application Risk Score with zero in the very first rule. It is quite different from the scorecard defined in the spec that relies on the default initialization with zero. There are 3 reasons why I don’t like this DMN convention: 1) it hides an important initialization logic; 2) the initial value can be different from 0; 3) we cannot use multiple scorecards for the same decision variable. Anyway, let’s continue. Do you think this small piece of the decision logic could be incorporated in other decision models?
READER. Probably not… In particular, this “logical piece” will be used to calculate Pre-Bureau Risk Category and Post-Bureau Risk Category, which have different calculation logic themselves. So, if they will be presented as separate decision models, the Application Risk Score logic can be be a part of any of them.
AUTHOR. Good reasoning. So, please complete the independent decision model “DetermineApplicationRiskScore” even if it actually has only one scorecard.
READER. Done. You can find all files Decision.xls, Rules.xls, and Glossary.xls in the folder “ApplicationRiskScore”. I also created the proper Data.xls file and successfully tested this decision model.
AUTHOR. We would not consider them now to save time. I guess now you should similarly define two remaining decision models for Pre-Bureau and Post-Bureau Risk Categories.
— Decision Model “Pre-Bureau Risk Category” — top
READER. We may represent the decision logic for calculation of the Pre-Bureau Risk Category almost exactly as in the spec:

I’ve incorporated this logic into an independent decision model “DeterminePreBureauRiskStrategy”: you can find all files Decision.xls, Rules.xls, and Glossary.xls in the folder “PreBureauRiskStrategy”. I’ve successfully tested this decision model against test data defined in the file “Data.xls”.
— Decision Model “Post-Bureau Risk Category” — top
READER. We may represent the decision logic for calculation of the Post-Bureau Risk Category almost exactly as in the spec:

I’ve incorporated this logic into an independent decision model “DeterminePostBureauRiskStrategy”: you can find all files Decision.xls, Rules.xls, and Glossary.xls in the folder “PostBureauRiskStrategy”. I’ve successfully tested this decision model against test data defined in the file “Data.xls”.
— Linking Loosely Coupled Decision Models Together — top
AUTHOR. So, now you successfully decomposed our “big” decision model into 7 smaller, loosely coupled decision services. Your repository looks as follows:

All decision models have been already independently tested. They are placed into sub-folders of the folder “Decisions” and have similar organization: Decision.xls, Rules.xls, and Glossary.xls. Of course, larger decision models can contain more xls-files that will be reflected inside the Environment table of the file “Decision.xls”. All test cases are located in sub-folders of the folder “Tests” under the same names as the corresponding decision models. In the real-world decision management systems it is extremely important to maintain both decision models and their tests, and such a parallel organization of the repository provides a good example of how to do it.
READER. I understand that now we will use these small (or relatively small) decision models as building blocks for our big decision. What is the best way to do it?
AUTHOR. If your system is already has a Business Process Management (BPM) engine in place, you can use these decision models as decision task of your business process. However, you may use a rule engine directly for composing big decision models out of smaller ones. OpenRules offers several integration methods. All these methods use a common Glossary that combines glossaries of all involved decision models. Such a “big” glossary serves as a spine that keeps all surrounding decision models together:
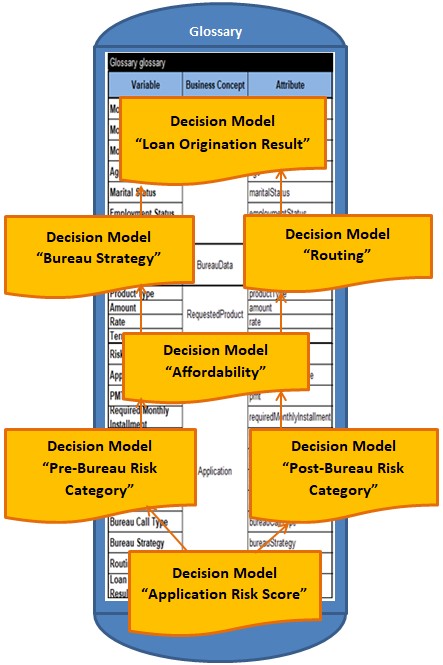
Our common glossary will look as follows:

And now I will show you two integration methods:
— Integration Method 1 “Importing Decision Models” — top
The first integration method expects that every “small” decision model will be automatically deployed as a separate decision using its own file “Decision.xls”. Thus, all “small” decision model remain completely independent of other decisions and can be simply “imported” into one “big” decision model. I will show you how to do it using a newly introduced OpenRules table of the type “DecisionImport”. Let’s create a new folder “ImportedDecisions” as a sub-folder of “Decisions”. Inside this folder we will create the file “Decision.xls” with the following table:

The first column refers to the full path of the file “Decision.xls” for every decision model we want to import into the new decision model. The second column contains to the names of the imported decision models, under which they will be known to the “big” decision. Sometimes, when internal decision names for two imported models are the same, we may use the third column to specify their external names.
Now I need to define the main table “DetermineLoanOrigination” for our “big” decision model and place it into its own file “Decision.xls”. Here is what I did initially:
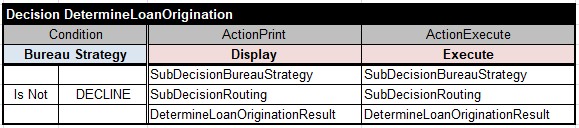
First, this decision will execute “SubDecisionBureauStrategy” that (as we already know) is supposed to assign a value ACCEPT, THROUGH, or DECLINE to the decision variable “Bureau Strategy”. Then, if Bureau Strategy Is Not DECLINE, this table will execute “SubDecisionRouting” that (as we already know) is supposed to assign a value ACCEPT, DECLINE, or REFER to the decision variable “Routing”. And finally this table will (unconditionally) execute the decision “DetermineLoanOriginationResult” to define the main output variable “Loan Origination Result”.
READER. I can see that the decision “DetermineLoanOriginationResult” was imported in the table “DecisionImport”, but where did you define sub-decisions “SubDecisionBureauStrategy” and “SubDecisionRouting”?
AUTHOR. You are right – I haven’t defined them yet. Here they go:
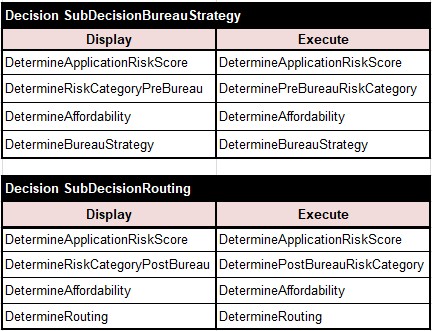
READER. I see – they simply execute other imported sub-decisions. It’s quite simple and intuitive. But I have a question: will the decision “DetermineApplicationRiskScore” be executed twice?
AUTHOR. Good catch! What would you do to avoid it?
READER. I guess I can move this decision to the main table “DetermineLoanOrigination”.
AUTHOR. OK, please do it.
READER. Here ate all three slightly “optimized” tables:
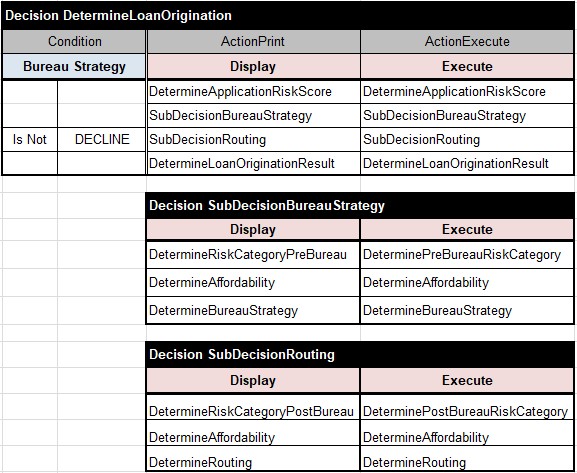
AUTHOR. Very good. And the Environment table for this “big” decision “DetermineLoanOrigination” should only contain references to the “big” glossary and the standard OpenRules templates:
 Now we need to test the integrated decision. It means we need to combine all test cases from out imported decision models and place them in one file “Tests/ImportedDecisions/Data.xls”. Below are combined tables for all involved business concepts. Here are Datatype and Data tables for Applicant:
Now we need to test the integrated decision. It means we need to combine all test cases from out imported decision models and place them in one file “Tests/ImportedDecisions/Data.xls”. Below are combined tables for all involved business concepts. Here are Datatype and Data tables for Applicant:

Here are Datatype and Data tables for RequestedProduct:
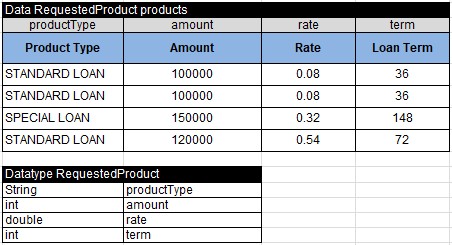
Here are Datatype and Data tables for BureauData:

Here are Datatype and Data tables for Application:

And finally, here are 4 test cases with expected results:

And now you may execute our “big” decision model using the standard bat-file “runImportedDecisions.bat”.
— Execution Results — top
READER. It seems working fine producing a long execution protocol. I noticed that the statement “INITIALIZE OPENRULES ENGINE” was repeated 8 times…
AUTHOR. It was expected for this integration method: separate instances of Decision and related OpenRulesEngine were created for the main decision model and each out of 7 imported decision models. It can be effectively used when all models are deployed on a web server and being created once are used many time by various concurrent users. Let’s look at the execution results of the Test 1.
READER. Here they are:

We can see how different decision models were actually executed along with produced values for related decision variable. The final output Loan Origination Result is ACCEPT as expected.
AUTHOR. It is interesting to compare these results with the results of the Test 2 where we made only one change – the same Applicant has an input variable Existing Customer set as FALSE (contrary to the value TRUE in the Test 1). Let’s look at the Test 2 results:

READER. I can see that the decision “DeterminePostBureauRiskCategory” now defines the variable “Risk Category” as MEDIUM (instead of VERY LOW in Test 1). As a result, the variable “Routing” and consequently “Loan Origination Result” receive value “DECLINE”.
AUTHOR. Good. Have you noticed the the output for TEST 3 and Test 4 are smaller to compare with Tests 1 and 2. Why is that?
READER. Here is the output for the Test 3:

Aha, I see: the sub-decision “SubDecisionRouting” never was executed. The explanation is in our main decision “DetermineLoanOrigination” that executes “SubDecisionRouting” when Bureau Strategy is not DECLINE, and here it is actually was assigned the value “DECLINE”.
— Integration Method 2 “Importing Decision Files” — top
AUTHOR. And to complete this session, I want to show you one more way of how loosely coupled decision models can be integrated in one “big” decision. Contrary to importing separately deployed decision models as in the previous method, we will combine all files with decisioning rules from “small” decision models and build One “big” Decision model model that uses all these files.
First, I need to copy the folder “ImportedDecisions” into the folder “OneDecision” inside the folder “Decisions”. I will also copy “Tests/ImportedDecisions/Data.xls” to “Tests/OneDecision/Data.xls”. The only required change in the Data.xls is in the Environment table:

Now it includes “../../OneDecision/Decision.xls” instead of “../../ImportedDecisions/Decision.xls”.
Now let’s make changes in the file “OneDecision/Decision.xls”. I’ve deleted the table “DecisionImport” as we will not use it anymore. Instead I will modify the Environment table inside this file as follows:
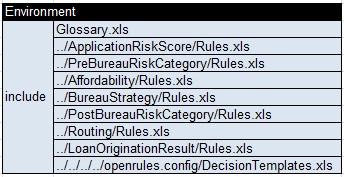
READER. That’s what we usually did earlier when our decision model required rules defined in different xls-files. I can see that you included all files “Rules.xls” from our 7 loosely coupled decision models.
AUTHOR. Correct. I also included “Glossary.xls” defined in the same folder “OneDecision”. It is exactly the same glossary that we used in the first integration method. Now, let’s look what changes I needed to make in the main tables of the type “Decision”:
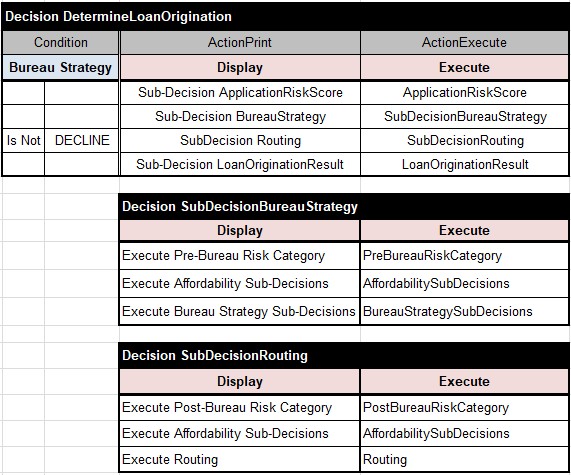
As you can see, now the column “Execute” contain the names of the main methods defined in the files “Rules.xls” (not in the files “Decision.xls”) of our 7 decision models.
That’s it. You may execute to create and execute the standard batch file “runOneDecision.bat”.
READER. It produces almost the same results as the previous method – at least all expected variables received expected values.
AUTHOR. If you look at the execution protocol, you will noticed that only one instance of OpenRulesEngine and one instance of Decision (“DetermineLoanOrigination”) were created.
CONCLUSION. We took a relatively complex decision problem described in the Section 11 of the DMN Specification. We decomposed the entire problem into 7 small loosely coupled decision models, each of whom utilized only basic DMN-like decision tables (avoiding duplication and use of functions or boxed expressions). All these decision tables have been tested independently. Finally then we demonstrated two different integration methods which allow a business user to combine already tested decision models into complete executable decisions. Everything was done in Excel using the OpenRules execution engine. The proposed solution describes in details how to organize a knowledge repository to support effective decision modeling, execution, and long-term maintenance.
