In an ideal world we would limit ourselves to Single-Hit decision tables that cover all possible combinations of the involved decision variables. However, DMN rightfully introduced so called “multiple hit” (or “multi-hit”) decision tables to stay closer to the decision modeling reality. Every time when a decision table creator thinks about situations when multiple rules may be satisfied for the purpose of aggregation of certain values or when rule overlapping with possible overrides may occur, the multi-hit tables come to play. DMN 1.0 describes 3 types of the multi-hit decision tables in the following way:
No order: returns all hits in a unique list in arbitrary order
Output order: returns all hits in decreasing priority order. Output priorities are specified in an ordered list of values. Allowed only for single output decision tables.
Rule order: returns all hits in rule order.
I have issues with choosing these 3 types. “No order” in general (within decision tables and between decision tables) deserves a separate discussion outside of this context. I agree with the DMN intention to reduce complexity and thus to omit other possible types of multi-hit tables (e.g. those described in PMML). To reduce complexity further, I’d omit both two types “N” and “O” as well. Working with decision tables for many years, I have not seen a significance of those 2 types: even the proper DMN examples do not show why these two types should be even mentioned. However, in many of practical situations people heavily rely on the third type “R” of decision tables currently called “Rule order”. In particular, rules down in the decision table usually override or complement (aggregate) previous rules defined above them. The DMN example

demonstrates the point (while it’s difficult to understand that 20% scholarship and 30% loan have been accumulated as an aggregation function “collect” is not explicitly shown).
What is really missing is an explanation how the “Rule Order” multi-hit policy actually works dealing with various real-world situations. Here is the explanation that I and (I believe the majority of my colleagues) consider as the default behavior of multi-hit decision tables:
- First, all rules are evaluated and if their conditions are satisfied, they are marked as “to be executed”
- Second, only actions of those rules that were marked as “to be executed” will be actually executed (again in the top-down order).
Thus, we should make two important observations about regular multi-hit decision tables:
- Rule actions cannot affect the conditions of any other rules in the decision table – there will be no re-evaluation of any conditions
- Rule overrides are permitted. The action of any executed rule may override or complement the action of any previously executed rule.
From this perspective multi-hit decision tables CANNOT be explained as a sequence traditional IF-THEN statements used by programmers:
Rule1: IF condition THEN action
Rule2: If condition THEN action
Rule3: IF condition THEN action
…
Multi-hit decision tables have quite different execution logic, but this logic is more natural for business analysts – read here why.
Now, let’s consider the following example:
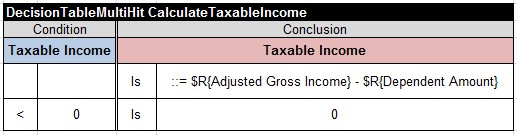
The first rule does the actual calculation of Taxable Income. The second rule is supposed to make Taxable Income to be equal to 0 if the calculated value is less than 0.
One may try to implement this logic as a regular multi-hit decision table as above. However, even if the first rule produces a negative value, the second rule would not be executed (unless an initial value of the Taxable Income was negative from the very beginning). So, we need at least to consider the second type of the multi-hit decision tables when:
- Rules are evaluated in the top-down order and if a rule condition is satisfied, then the rule actions are immediately executed.
- The action of any executed rule may affect the conditions of the rules that follow this rule. Thus, next rules may override or complement previously executed rules.
We, at OpenRules, call such multi-hit table “Sequence”:

This multi-hit table of the type “DecsionTableSequence” different from the default one “DecisionTableMultiHit”. Its execution logic is a more traditional for programmers. In one of our pre-DMN discussion, Gary Hallmark labeled this approach as the one with a “side effect” that in general should be avoided by DMN. We also usually encourage our customers the use mainly the standard types of decision tables: “DecisionTableSingleHit” and “DecisionTableMultiHit”. However, in real world it is difficult to avoid tables of the type “DecisionTableSequence” unless we force a user to create separate tables for different conditions. Especially popular types of sequence-tables are the tables called “Decision”, which are used to represent inter-decisioning logic like in this example:

Here the sub-decision “DecisionValidateTaxReturn” sets the decision variable “1040EZ Eligible” to TRUE or FALSE. Then based on the calculated value of this decision variable, this multi-hit decision table will execute (or not!) the sub-decision “DecisionCalculateTaxReturn”. The topic of regular vs. sequence multi-hit tables was also discussed in detail in this post.
So, my suggestion for DMN 1.1 is to limit the standardized multi-hit tables to only two types whichever names for them will be selected:
- Multi-hit type 1: The default type with pre-evaluated rules (and no “side effects”)
- Multi-hit type 2: The sequences.
I am looking forward to other practitioners sharing their experience with different types of multi-hit decision tables.
P.S. I will explain my resistance to decision tables with priorities in a separate post.

Thanks for a thought provoking article. I share your understanding of the semantics of multi-hit tables – that there is no re-evaluation of conditions during the rule execution and that the consequences of some rules can override others. These observations are not explicit in the DMN spec as far as I know (which is a shame).
I can also see a case for removing hit policy “O” (and indeed “P”) as I have never seen a client need this and there are better ways to achieve this effect. However I feel that hit policy “N” is worthy of retention and I’m curious to know why you shun it. Why do we need “N”? I would argue that often, even on the majority of occasions, if you need to yield a ‘collection’ conclusion, you don’t care about the order of that collection’s contents. Furthermore, you want to actively document a lack of semantics for order in the collection to prevent consumers of the conclusion from depending on order. Take your first example – what is the semantic distinction between [ 20% Scholarship, 30% Loan ] and [30% Loan , 20% Scholarship] – are the contents of this collection not orthogonal? Forgive me if I have misunderstood, but why is order important here?
In addition I must confess to being very skeptical about the notion of sequence multi-hit tables. In general I feel that decision models should be declarative and that sequence dependent documentation is best avoided. I know it appeals to programmers, but often I find that sequence is unnecessary and it’s my experience that it can make a decision table very hard to understand – which defeats the mean goal of DMN: to communicate requirements. Worse, sequenced decision tables don’t scale very effectively (just like “F” and “P” hit policy tables) and violate the atomicity of decision logic. Authors of sequential rules can often get carried away trying to squeeze all their logic into one big decision table – very often the result resembles a Visual Basic script! The problem is that there a temptation to mix implementation detail with a specification of requirements. In my view sequence tables can, and should, be avoided and that doing so promotes clarity, separation of concerns and ease of maintenance.
I note that you advise your clients to use DecisionTableSequence only when really necessary (a sentiment with which I wholeheartedly agree) and I’d be keen to see a ‘killer use case’ for this. Surely sequence can always be avoided though the use of inferential relationships?
Regards,
Jan (Purchase)