
Decision tables is the most popular mechanism for representation of business logic – no wonder they play the major role in the DMN standard. However, when it comes to analyzing large amount of data, standard decision tables may not be the best way to do it. In this post, I’ll describe a much better approach implemented in OpenRules.
Let’s consider a simple example borrowed from the OpenRules tax calculation decision project “1040EZ”:

This decision table is actually a lookup table that contains 50,000 rows. While in teh decision tables rows usually represent business rules, each row in this table hardly could be called a “rule”. These 50,000 rows represent data and thus, it is more natural to save them in an external file. e.g. in the CSV format. Let’s call this file “1040EZTaxTable.csv”, and here is how it may look:

We may replace the above decision table with the following table of the type “BigTable” that simply refers to our CSV file as [1040EZTaxTable.csv]:
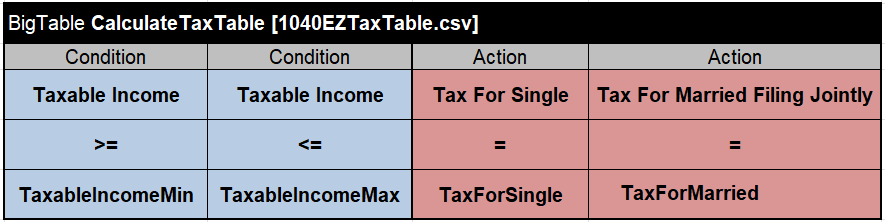
This “BigTable” describes only business logic of how we want to treat our “big data” described in the CSV file. As usual, the second row contains keywords for conditions and actions and the third row contains decision variables defined in the Glossary. However, the 4th row contains comparison operators applied to every Condition and Action columns of this decision table. The 5th row contains the names of the columns in the CSV file. Thus, this BigTable will sear data rows in the CSV file applying to them the following business rule:
IF Taxable Income >= TaxableIncomeMin AND Taxable Income <= TaxableIncomeMin
THEN Tax For Single = TaxForSingle AND Tax For Married Filing Jointly = TaxForMarried
The first very important advantage of such representation has is the separation of data and business logic (rules). You may easily modify your data in the CSV file without any changes in the business logic.
You still may use the keyword “DecisionTable” instead of “BigTable”, however for large data files you will lose another important advantage of this representation, namely superfast performance. Contrary to the standard DecisionTable, the BigTable uses a special execution algorithm based on the self-balancing binary search. When datasets include thousands or hundreds of thousands rows, BigTable is 10-100 times faster than Decision Table.
Instead of the Using CSV files is frequently a preferred way to maintain large data arrays that allows our decision tables to deal only with business logic.
This table uses the keyword “BigTable” instead of “DecisionTable”. Its major advantages is superfast performance: for very large lookup tables with hundreds of thousands of rows BigTable is 10-100 times faster to compare with DecisionTable (see a benchmark)
Like a regular DecisionsTable, the table of the type “BigTable” by default is a single-hit table. However, you may use BigTableMultiHit to accumulate some values. For example, our sample project “ICD10” compares medical claim diagnosis codes with some incompatible codes described in this file “ICD10Codes.csv”:
Column 1,Column 2
A48.5,A05.1
K75.0,A06.4
K75.0,K83.09
K75.0,K75.1
….
The following BigTable finds out if the decision variable “Diagnosis Code” is “Found in Column 1” and accumulates all matching codes from the Column 2 in the decision variable “Matches in Column 2” which is defined in the glossary as String[] (an array of strings):

Similarly, this BigTable works with diagnoses in Column 2 of the same CSV file:

We may combine these two tables in one BigTableMultiHit:

If you want to know which row in the CSV file satisfies your conditions you may use your own Integer decision variable such as “Row Number” in the Action and the special value # as shown in the following table:

The numeration of rows starts with 1 and if there is no row in the CSV file that satisfies all conditions then Row Number will be 0.
So, the BigTable may contain multiple rules, e.g. the above table “AnalyzeCodesInFile” contains 2 rules. Their logic specifies how to conduct a search inside data large CSV files.
CONCLUSION. OpenRules offers a very practical and highly efficient approach to for decision models that deal with large datasets:
- Use CSV files to specify your large datasets;
- Use decision tables of the type “BigTable” to specify business logic for handling these CSV files.
